1. Architektur
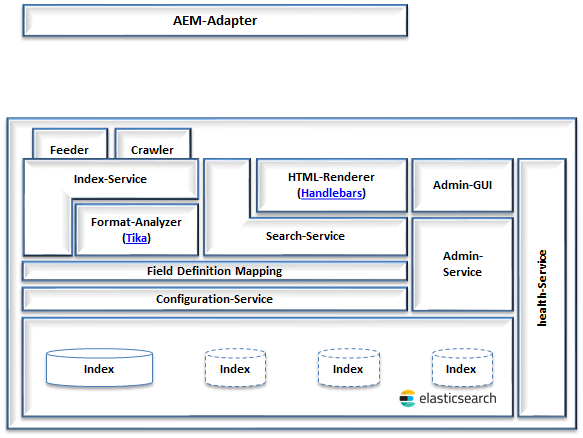
| Komponente | Beschreibung | Dokumentation |
|---|---|---|
Elasticsearch |
Basis-Suchmaschine. |
|
Index |
Datenspeicher. Enthält indexierte Dokumente die sich aus Feldern und Feldinhalten zusammensetzen. |
|
Configuration-Service |
Enthält Endpunkte für die Speicherung aller Konfigurations-Einstellungen im Konfigurations-Index. |
|
Admin-Service |
Vermittelt die Konfigurations-Einstellungen von der Admin-GUI zum Configurations-Service. |
|
Admin-GUI |
Stellt die GUI für die Eingabe der CSA-Konfigurationseinstellungen zur Verfügung. |
|
Index-Service |
Bietet Endpunkte für die Indexierung von Daten an. |
|
Format-Analyzer |
Basiert auf Apache tika und analysiert die im Index-Service übergebenen Dokumente und Felddaten. |
|
Search-Service |
Bietet parametrisierbare Endpunkte zum Durchsuchen des Index nach Suchkriterien an. |
|
HTML-Renderer |
Rendert das Suchergebnis nah HTML. |
|
Templates |
Enthalten den Handlebars-Code zum Rendering des HTML. |
|
health-Service |
Bietet Endpunkte für die Überwachnung der CSA |
|
Note
|
Analyzer
Die Indizierung von Textfeldern erfolgt intern über Analyzer, in denen die jeweiligen Wörter einer Sprache enthalten sind. Analyzer analysieren die Texte der Felder die im Field Definition Mapping angegeben sind. Pro Analyzer kann eine Blacklist verwaltet werden. Die Namen der Blacklist entsprechen dem Namen des entsprechenden Analyzers. Die in einer Blacklist gespeicherten Worte werden beim Indexieren vom Analyzer ignoriert und nicht in den Index überführt. |
2. Server-Architektur und Konfiguration
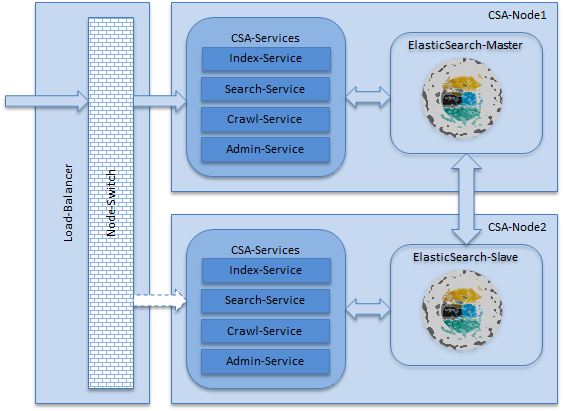
| Komponente | Funktion |
|---|---|
Load-Balancer |
Empfängt die Requests und reicht diese an den Node-Switch weiter. |
Node-Switch |
Implementiert automatisches Failover:
|
CSA-Services |
Stellt Index-, Search-, Crawl-, und Admin-Service zur Verfügung |
Index-Service |
sendet Heartbeats ("am alive") Events an den Node Switch |
Search-Service |
sendet Heartbeats ("am alive") Events an den Node Switch |
Crawl-Service |
sendet Heartbeats ("am alive") Events an den Node Switch |
Admin-Service |
sendet Heartbeats ("am alive") Events an den Node Switch |
ES-Master-Node |
Der Elastic-Search Master Node |
ES-Slave-Node |
Der Elastic-Search Slave Node |
3. Allgemeine Benutzung der CSA
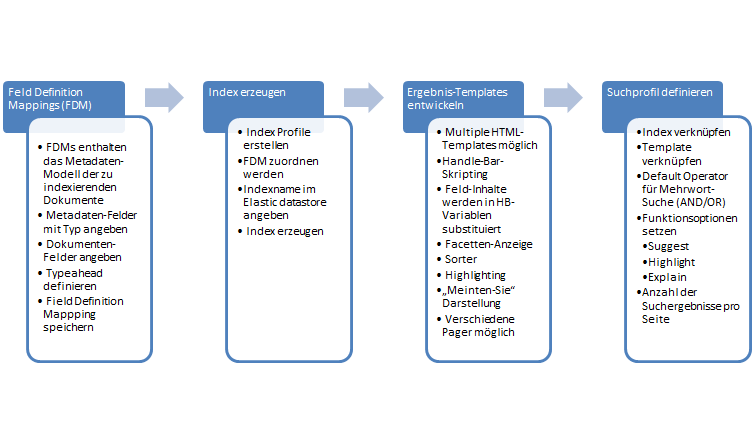
Die folgende Schritte sind notwendig, um eine Suche in Betrieb zu nehmen. Über die Admin-GUI (http://<server>:8080, Account: admin, admin) müssen folgende Schritte durchgeführt werden:
-
ein Mapping (Field Definition Mapping) anlegen
-
einen Index anlegen
-
Dokumente in den Index indexieren
-
ein Template für das Rendering von Suchergebnissen anlegen
-
ein Such-Profil anlegen, in dem die Parameter gesetzt werden mit denen ein Suchrequest absetzt wird.
Über die Admin-GUI ein Suchprofil mit dem Profil aus Schritt 1c und Template aus Schritt 1b anlegen
-
Das Suchfeld mit Suchvorschlägen (typeahead) in eigene Suchseite intergrieren Das typehead-JSScript z.B jquery-typeahead muss eingebunden werden, wobei die Daten über den Endpoint
http://<server>:8080/search/typeaheadabgerufen werden muss. Wenn sich aber die Suchseite und der Search-Service auf unterschiedlichen Domains befinden, muss jsonp mit callback für den typeahead-Call eingesetzt werden. Dazu muss der Endpoint zur Typeaheadhttp://<server>:8080/search/typeaheadJsonpumgeändert werden, siehe Test GUI. als Beispiel. Bei dem Aufruf von typeahead-endpoint ist das aus Schritt 3 definierte Suchprofil als spr (oder searchprofile)-Paramater anzugeben -
CSA_Suchergebnis in eigene Suchergebnisseite einbetten Dies ist z.B mittels ajax möglich. Auf der Suchergebnis-Seite sollte ein Bereich (z.B
<div id="csa-searchresult-content"></div>) definiert werden. Die Suche wird per ajax gelöst, als Response bekommt der Client einen HTML-Content zurück. Dieser Content ist dann in das HTML des reservierten Bereichs (wie im Beispielcsa-searchresult-content) zu füllen. Bei dem Aufruf von search-endpoint ist das aus Schritt 3 definierte Suchprofil als spr (oder searchprofile)-Paramater anzugeben Wenn sich die Suchseite und der Search-Service auf unterschiedlichen Domains befinden, muss jsonp mit callback für die Suche eingesetzt werden. Dazu muss der callback-Parameter übergeben werden.
4. CSA - GUI
Die Administrations GUI dient der Verwaltung der Datenstrukturen der CSA.
4.1. URL der Admin-GUI
Die Administrations-GUI ist erreichbar unter:
http://<Domainname>:80804.2. Anmeldung an der CSA
Die Benutzung der Administrations-GUI erfolgt über die Anmeldung an der Administrations-GUI.
Die Anmeldung erfolgt im Anmelde-Dialog über die Eingabe von Username/Passwort und Auswahl des Login-Buttons.
4.2.1. Das Hauptmenü
Das Hauptmenü der CSA-Administrations-GUI enthält alle Links auf die für die Konfiguration notwendigen Konfigurationsseiten. Die Auswahl eines Menüpunkts aktiviert die jeweilige Konfigurationsseite im rechts vom Menü gelegenen Content-Bereich. Jede Konfigurationsseite ist immer erreichbar.
Funktionen des Hauptmenüs
| Screenshot des Hauptmenüs | Menüpunkt | Funktion |
|---|---|---|
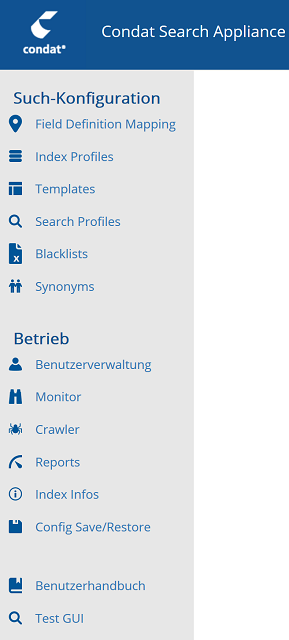
|
Verwaltung von Feld Definition Mappings (FDM) mit der die Feld-Strukturen von Suchindexen definiert werden. |
|
Verwaltung von Index Profilen mit der die Zuordnung von FDMs zu Such-Indexen erfolgt. |
||
Verwaltung von Handlebar-Templates für das HTML-Rendering von Suchergebnissen. |
||
Verwaltung von Suchprofilen mit denen Suchergebnisse konfiguriert werden. |
||
Verwaltung einer Blacklist, mit der Worte aus der Suche ausgeschlossen werden können. |
||
Verwaltung von Synonymlisten, mit der synonyme Worte in der Suche zurückgegeben werden. |
||
Einrichtung von Benutzer und Gruppen für die CSA-Services |
||
Betriebsstatus der CSA-Services |
||
Übersicht der laufenden Crawler |
||
Dashboard mit Statistiken über die Nutzung der CSA-Services |
||
Index Infos |
Zustand der CSA-Indexe |
|
Config Save/Restore |
Speicherung und Wiederherstellung der Konfigurationen der Administratoions-Objekte |
|
Speicherung und Wiederherstellung von Indexen |
||
Benutzerhandbuch |
Das Benutzerhandbuch der CSA. |
|
Test GUI |
Eine Beispiel-Suchseite mit allen Features der CSA. Hier können die konfigurierten Search Profiles ausgewählt werden. Es werden Suchergebnisse angezeigt und das konfigurierte Template benutzt. Auch auf die JSON Ausgabe kann umgeschaltet werden. |
4.3. Field-Definition-Mapping-Konfiguration
4.3.1. Konfiguration
Über die Konfiguration des Field Definition Mappings (FDM) wird das Datenmodell der Dokumente im Index definiert. Ein FDM besteht aus einem Namen und einer Feldliste, die das Datenmodell des zu indexierenden Dokuments beschreiben. Die Felder eines Dokuments können dabei verschiedene Datentypen enthalten, die entsprechend im Index abgelegt werden. Die Interpretation eines Datentypen beim Indexieren erfolgt über einen Analyzer, mit dem angegeben wird, in welche Sprache die Daten eines Feldes vorliegen und interpretiert werden müssen.
Benutzeroberfläche
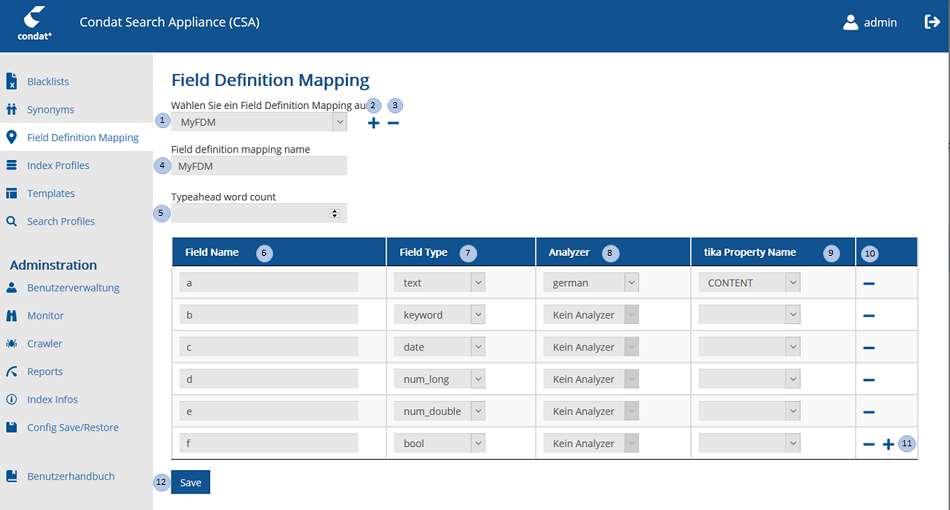
Eingabe-Elemente der FDM-Konfiguration
| Nr. | Eingabe-Element | Funktion |
|---|---|---|
1 |
FDM-Selection-Drop-Down |
Ermöglicht die Auswahl einer zu editierenden FDM aus einer Liste der gespeicherten FDMs. Mit der Auswahl einer FDM aus der Liste wird die ausgewählte FDM geladen. |
2 |
Add-FDM-Button |
Button mit dem zu einem Analyzer eine FDM hinzugefügt werden kann. Mit Auswahl des Buttons wird die Editiermaske zurückgesetzt. |
3 |
Remove-FDM-Button |
Die aktuelle FDM wird gelöscht. Die Löschung erfolgt erst nach dem im Verifikationsdialog "Möchten Sie die FDM löschen?" mit "Ja" selektiert wurde. |
4 |
FDM-Name-Textfield |
Feld enthält den Namen des aktuell bearbeiteten FDMs. Zum Kopieren von FDMs kann hier bei einem existierenden FDM ein neuer Name eingetragen werden. Das Speichern erzeugt einen neuen Eintrag. |
5 |
FDM-Typeahead-Wordcounter |
Mit diesem Wert wird gesteuert wie viele Worte innerhalb eines Typeahead-Vorschlags angezeigt werden sollen. Der Wertebereich ist numerisch und geht von 1-5. |
6 |
FDM-Field-Name-TextField |
Feld enthält den Names eines Feldes, das im Index abgelegt werden soll. |
7 |
FDM-Field-Type-Drop-Down |
Datentyp des Feldes das im Index abgelegt werden soll. Die Datentypen sind: text, keyword, date, num_long, num_double, bool und not_searchable. Nur Felder vom Datentyp=text können für die Volltextsuche benutzt werden. Die Datentypen keyword, date, num_long, num_double, bool werden für Filterungen und Scoring benutzt. Der Datentyp not_searchable ist für Felder vorgesehen, die nicht innerhalb der CSA verwendet werden, sondern genau so ausgegeben, wie sie indexiert wurden. Der Datentyp kann als Value ein Einzelwert oder Array vom Typ keyword, date, num_long, num_double, bool sein, aber auch ein komplett strukturiertes JSON Object oder JSON Array. Der Datentyp hat kein Analyzer, weil das Value nicht analysiert wird, kann aber ein tika Property Name haben. Soll ein Feld sowohl in der Volltextsuche und als auch als zb Facette benutzt werden, so muss für dieses Feld zwei Einträge (mit unterschiedlichen Field Name) in der FDM vorgesehen werden. |
8 |
FDM-Field-Analyzer-Drop-Down |
Angabe des Analyzers mit dem der Feldinhalt analysiert wird. Der entsprechende Analyzer ist auszuwählen. Nur Felder vom Feld-Type=text können einen Analyzer bekommen und sind Teil der Volltextsuche. |
9 |
FDM-Field-Tika-Property-Drop-Down |
Indexierte Dokumente (.html,.pdf) werden durch TIKA analysiert und die Daten in TIKA-Felder geschreiben, die zum Field-Definition-Mapping-Feld zugeordnet werden. Die TIKA-Felder die ausgewählt werden können sind: TITLE, CONTENT, KEYWORDS, COMMENT, DESCRIPTION, RiGHTS, CREATED, CREATOR, MODIFIED, MODIFIER, CONTRIBUTOR, COVERAGE, FORMAT, LANGUAGE, PRINT_DATE, PUBLISHER; SOURCE; TYPE, META (zum Indexieren von HTML-Metadaten, s.u.)] |
10 |
Remove-FDM-Field-Button |
Mit diesem Buton wird das aktuelle FDM-Feld gelöscht. |
11 |
Add-FDM-Field-Button |
Mit diesem Button kann ein neues FDM-Feld angelegt werden. |
12 |
Save-FDM-Button |
Mit diesem Button wird das editierte FDM unter dem im Feld FDM-Name-Textfield spezifierten Namen gespeichert. |
4.3.2. Indexieren von HTML-Metadaten
Zum Indexieren von HTML-Metadaten mit einem Wert
<meta name="process" content="/taxonomy/process/distribution"/>oder
<meta name="farbe" content="rot" />
<meta name="farbe" content="schwarz" />
<meta name="farbe" content="grün" />mehreren Werten in einem Feld muss ein Mapping in einem besonderen Format angelegt werden.
Das HTML-Metadatum muss mit dem Präfix "meta_" beginnen und es muss auf das tika-Property "META" gemappt werden:
| Field Name | tika Property Name | Beschreibung |
|---|---|---|
meta_<Metadaten-Name> (z.B. meta_process) |
META |
Falls diese Metadaten vom Type=text sind und einen Analyzer zugeordnet bekommen haben, dann werden für die Volltextsuche alle HTML-Elemente für die Suche entfernt.
Beispiel: meta_baum= |
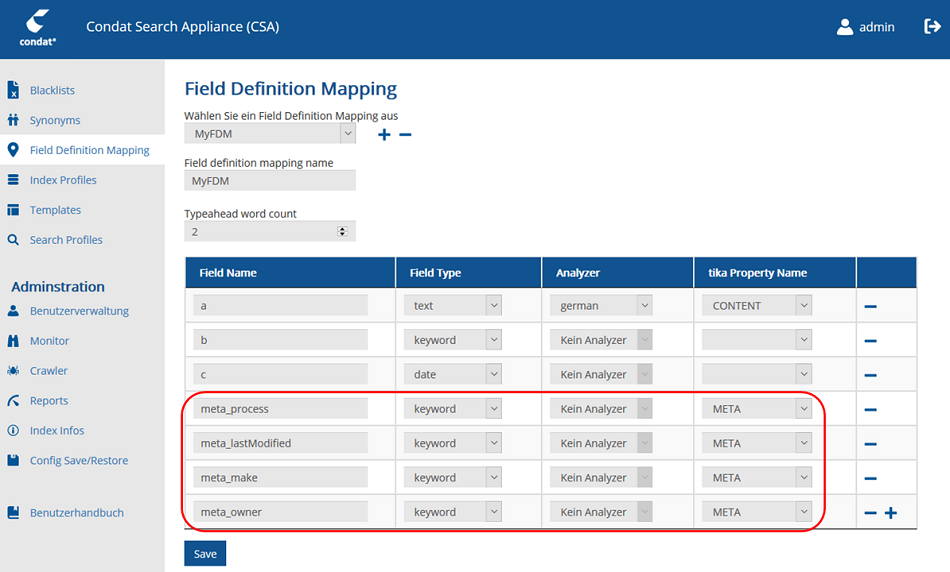
4.3.3. Schritt-für-Schritt-Anleitung
Neues FDM anlegen
-
Klicken Sie den Add-FDM-Button (2). Alle Felder werden zurückgesetzt.
-
Geben Sie im FDM-Text-Feld den Namenn unter dem das neue FDM gespeichert werden soll, ein.
-
Selektieren Sie, die Wortanzahl, die im Typeahead gespeichert werden soll (1-5).
-
Definieren Sie mindestens ein FDM-Feld.
-
Geben Sie einen FDM-Feldnamen im FDM-Field-Name-TextField ein.
-
Selektieren Sie den Feldtyp im FDM-Field-Type-Drop-Down.
-
Selektieren Sie im FDM-Field-Analyzer-Drop-Down den Analyzer, mit dem der Feldtyp analysiert wird.
-
Soll das Feld einem TIKA-Feld entsprechen, so selektieren Sie im FDM-Field-Tika-Property-Drop-Down das zugeordnete TIKA-Feld.
-
Spezifieren Sie mit dem FDM-Field-Typeahead-Selector, ob das Feld für Typeahead berücksichtigt werden soll.
-
Weitere FDM-Felder können mit den Add-FDM-Field-Button angelegt werden.
-
Das aktuelle FDM-Feld kann über den Remove-FDM-Field-Button gelöscht werden.
-
Speichern Sie das FDM mit der Auswahl des Save-FDM-Button.
Bestehendes FDM editieren
-
Selektieren sie aus dem FDM-Selection-Drop-Down das FDM, das Sie editieren möchten. Die Daten des selektierten FDM wird in den Editor geladen.
-
Fügen Sie das FDM entsprechend Ihrer Anforderungen hinzu.
-
Ändern Sie den Typeahead-Wordcounter durch Veränderung des Werts im FDM-Typeahead-Wordcounter.
-
Fügen Sie FDM-Felder hinzu oder löschen sie Felder. Jedes Feld muss Namen, Feldtyp und Analyszer haben. Optional sind Werte im FDM-Field-Tika-Property-Drop-Down und FDM-Field-Typeahead-Selector.
-
Vergessen Sie niemals, die Änderungen durch Klicken des Save-FDM-Button zu speichern.
Bestehendes FDM löschen
-
Wählen Sie im FDM-Selection-Drop-Down das zu löschende FDM aus.
-
Klicken Sie den Remove-FDM-Button zum Löschen des ausgewählten FDM.
4.3.4. Technische Dokumentation
Die Dokumentation der Schnittstellen finden sie unter Field Definition Mapping.
4.4. Index-Profiles-Konfiguration
4.4.1. Einleitung
Mit einem Index-Profile wird
-
die Verknüpfung der Field Definition mit dem Index verwaltet,
-
ein Index angelegt und
-
definiert, welche Dokument-URLs indexiert werden und
-
welche abgelehnt werden.
4.4.2. Benutzeroberfläche
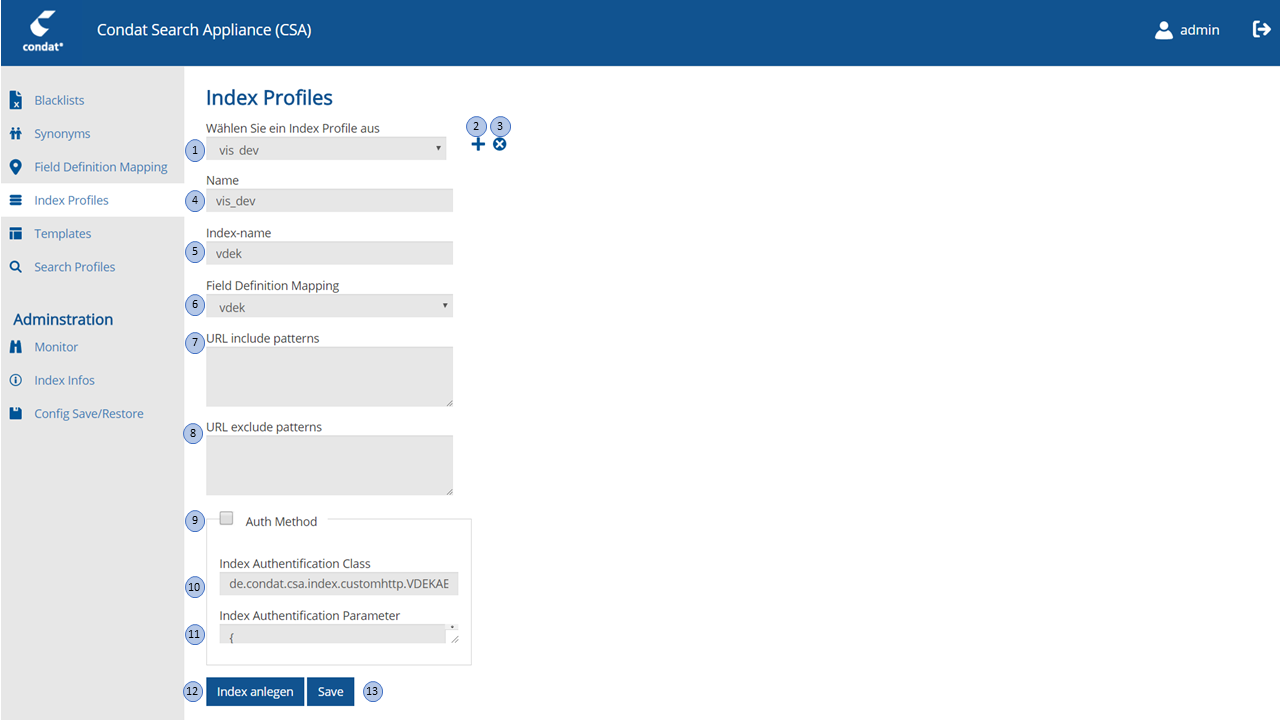
| Nr. | Eingabe-Element | Funktion |
|---|---|---|
1 |
IndexProfile-Selection-Drop-Down |
Ermöglicht die Auswahl eines zu editierenden IndexProfile aus einer Liste der gespeicherten IndexProfiles. Mit der Auswahl eines Index Profile aus der Liste wird das ausgewählte Index Profile geladen. |
2 |
IndexProfile-Add-Button |
Button mit dem ein neues Index Profile hinzugefügt werden kann. Mit Auswahl des Buttons wird die Editiermaske zurückgesetzt. |
3 |
IndexProfile-Remove-Button |
Das aktuelle IndexProfile wird gelöscht. Die Löschung erfolgt erst nach dem im Verifikationsdialog "Möchten Sie die IndexProfile löschen?" mit "Ja" selektiert wurde. |
4 |
IndexProfile-Name-Textfield |
Feld enthält den Namen des aktuell bearbeiteten IndexProfiles. |
5 |
IndexProfile-Name-Textfield |
Feld enthält den Namen des in der CSA erzeugten Index. Empfehlenswert ist, diesen mit dem IndexProfile-Name gleichzusetzen. |
6 |
IndexProfile-FDM-Selection-Drop-Down |
In dieser Auswahl wird das Field Definition Mapping verknüpft, das im Index angelegt werden |
7 |
IndexProfile-URL-Include-pattern-Textfield |
Angabe aller Pfade, die beim Indexieren von Dokumenten berücksichtigt werden sollen. |
8 |
IndexProfile-URL-Exclude-pattern-Textfield |
Angabe aller Pfade, die beim Indexieren von Dokumenten ausgeschlossen werden sollen. |
9 |
IndexProfile-useAuthClass-CheckBox |
Mit der Selektion dieser Checkbox wird spezifiziert, dass eine Authentifizierungs-Klasse für die Erreichbarkeit einer zu indizierenden Ressource benötigt wird. |
10 |
IndexProfile-useAuthClass-authClass-TextField |
Ein Textfeld, in dem eine Klasse (inkl. package-Pfad) angegeben wird, in der die Authentifizeirungs-Methode für den Zugriff auf die zu indexierenden Ressourcen ausgeführt wird. |
11 |
IndexProfile-useAuthClass-autParms-MultilineTextField |
Ein merhzeilige Textfield, in dem eine .json-Parameter-Struktur eingegeben wird, die der in authClass angegebenen Klasse übergeben wird. Die .json-Struktur enthält mindestens Username/Passwort für die Ausführung der Authentifizierung. |
12 |
IndexProfile-CreateIndex-Button |
Button zum Erzeugen eines Index, der dem aktuell editierten Index Profile entspricht. ACHTUNG: Mit dem Anlegen eines neuen Index werden alle bereits darin vorhanden Daten im Index gelöscht. |
13 |
IndexProfile-Save-Button |
Button mit dem das editierte Index-Profile gespeichert wird. |
Schritt-für-Schritt-Anleitungen
Anlegen eines neuen Index Profiles
-
Klicken Sie den Add-IndexProfile-Button (2). Alle Felder werden zurückgesetzt.
-
Geben Sie im IndexProfile-Name-Textfield (4) den Namen ein unter dem das neue Index-Profile gespeichert wird,
-
Geben Sie im Index-Name-Textfield (5) den Namen des Index ein, der in der CSA angelegt werden soll. Für die bessere Zuordnung des Index zum IndexProfile sollte der Index-Name dem Index-Profile-Namen (4) entsprechen.
-
Verknüpfen Sie ein Field Definition Mapping mit dem Index-Profile (5). Da das FDM das Datenmodell des zu erzeugenden Index enthält, ist eine Zuordnung zu einem FDM zwingend notwendig.
-
Geben Sie bei Bedarf in IndexProfile-URL-Include-pattern-Textfield (7) oder IndexProfile-URL-Exclude-pattern-Textfield (8) Pfade an, die beim Indexieren explizit abgelehnt oder explizit eingeschloßen werden.
-
Legen Sie mit dem IndexProfile-CreateIndex-Button (9) mit der Konfiguration des Index Profiles einen neuen Index an.
-
Klicken Sie auf den IndexProfile-Save-Button (10) zum Speichern des Index-Profiles
Editieren von gespeicherten Index-Profiles
-
Selektieren Sie aus dem IndexProfile-Selection-Drop-Down (1) das Index Profile, dass Sie editierenden möchten. Die Daten des gewählten Index Profiles werden in den Editor geladen.
-
Passen Sie das Index Profile nach Ihren Anforderungen an.
-
ACHTUNG: Änderungen am zugeordneten FDM, Index-Namen erfordern das Neuanlegen des Index mit dem eine vollstängige Datenlöschung verbunden ist. Klicken Sie zu dem Zweck den IndexProfile-CreateIndex-Button (9).
-
Klicken Sie auf den IndexProfile-Save-Button (10) zum Speichern des Index-Profiles.
Löschen von gespeicherten Index Profiles
-
Selektieren Sie aus dem IndexProfile-Selection-Drop-Down (1) das Index Profile, dass Sie löschen möchten. Die Daten des gewählten Index Profiles werden in den Editor geladen.
-
Klicken Sie auf den Remove-IndexProfile-Button
-
Sie werden über einen Bestätigungsdialog aufgefordert den Löschvorgang mit Klicken auf "Ja" zu bestätigen oder mit "Nein" abzubrechen.
Include- und Exclude-Patterns
Es kann vorkommen, dass man beim Anlegen eines Indexes eine Baumstruktur indexiert. Baumstrukturen enthalten das Problem, dass bei Angabe eines auszuschliessenden Baumknotens der gesamte darunter liegedende Unterbaum ausgeschlossen wird. Um nun innerhalb des auszuschliessenden Umterbaums einzelne Äste wiederum in der Indexierung berücksichtigen zu können, kann man mit den Feldern IndexProfile-URL-Include-pattern-Textfield (7) und IndexProfile-URL-Exclude-pattern-Textfield (8) die Pfade der Unterbaume und Äste spezifizieren, die explizit ein- bzw. ausgeschlossen werden sollen.
-
Laden Sie ein Index Profile (1) oder legen Sie ein neues Index Profile (2) an.
-
Geben Sie im IndexProfile-URL-Include-pattern-Textfield (7) pro Zeile im Feld einen Pfad eines Unterbauemes an, dessen Dokumente indexiert werden sollen.
-
Speichern Sie das Index Profile (10).
-
Laden Sie ein Index Profile (1) oder legen Sie ein neues Index Profile (2) an.
-
Geben Sie im IndexProfile-URL-Exclude-pattern-Textfield (8) pro Zeile im Feld einen Pfad eines Unterbauemes an, dessen Dokumente bei der Indexierung ausgeschlossen werden sollen.
-
Speichern Sie das Index Profile (10).
Authentification-Klasse verwenden
Viele CSA-Consumer-Systeme (z.B. AEM) in denen die zu indexierenden Inhalte (Contents) enthalten sind, erlauben nur authentifizierten Zugriff auf diese.
Der Indexierungsprozess der CSA enthält
-
im 1. Schritt einen Request auf eine URL des zu indexierenden Dokuments (URL des Dokuments).
-
Im 2. Schritt schickt der CSA-Index-Service einen Request an die übergebende Dokument-URL, um die TIKA-Analyse und die konkrete Indexierung der Inhalte des Dokuments durchzuführen. Ist der Zugriff auf das Dokument nur durch einen authentifizierten User möglich, muss eine Möglichkeit geschaffen werden, die Authentifizierung und die Authorisierung auf die URL herzustellen.
Da die Authentifizierung abhängig ist vom Consumer-System ist, wurde eine allgemeine Lösung geschaffen , diese für jede CSA-Instanz konfigurativ zu individualisieren. Die konfigurative Indivilualisierung erfolgt dadurch, dass die CSA-Administration des Index-Service eine Konfiguration enthält mit der 2 Werte gesetzt werden können:
-
auth-class: eine Klasse, die die Implementierung der individuellen Authentifications-Methodik enthält.
-
auth-parms: eine .json-Parameter-Struktur (die in der Regel mindestens Username/Passwort)
| auth-class | auth-params | Beschreibung | ||
|---|---|---|---|---|
de.condat.csa.index.customhttp.AEMHttpAuth |
|
Authentisierung zum AEM über das Login-Formular. Der Wert für http_hard_timeout_sec_S ist per Default auf 300 gesetzt und ist optional. |
||
<leer> |
|
Authentisierung zum AEM über das Login-Formular mit Hilfe der Default Index Authentification Class. In authFormParam können beliebige Parameter angegeben werden. |
||
<leer> |
|
Authentisierung über Basic-Auth. |
Implementierungseitig wird die auth-class mit der übergebenen auth-parms über einen Reflection-Mechanismus ausgeführt, um eine evtl. benötigte Authentifizierung auf die gewünschte Ressource durchzuführen.
-
Aktivieren Sie die Checkbox IndexProfile-useAuthClass-CheckBox
-
Spezifizieren Sie in IndexProfile-useAuthClass-authClass-TextField den Packepfad und die Klasse, in der die Authentifizierungs-Methode enthalten ist.
-
Spezifizieren Sie in IndexProfile-useAuthClass-authParms-TextField die .json-Struktor mit der 0
4.4.3. Technische Dokumentation
Die Dokumentation der Schnittstellen finden sie unter Index Profile.
4.5. Search-Profiles-Konfiguration
4.5.1. Einleitung
Mit Search-Profiles werden Suchkonfigurationen verwaltet.
4.5.2. Benutzeroberfläche
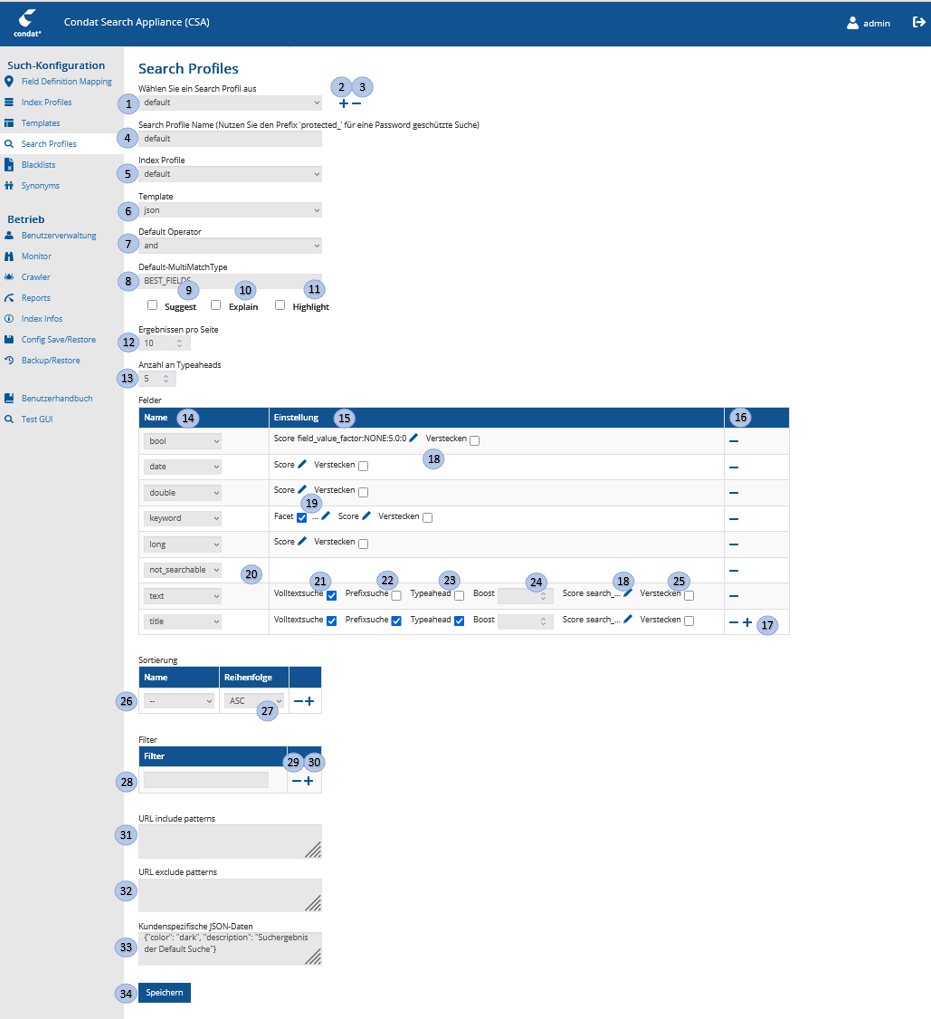
| Nr. | Eingabe-Element | Funktion |
|---|---|---|
1 |
SearchProfile-Selection-Drop-Down |
Ermöglicht die Auswahl eines zu editierenden Search Profile aus einer Liste der gespeicherten Search Profiles. Mit der Auswahl eines Search Profiles aus der Liste wird das ausgewählte Search Profile geladen. |
2 |
SearchProfile-Add-Button |
Button mit dem ein neues SearchProfile hinzugefügt werden kann. Mit Auswahl des Buttons wird die Editiermaske zurückgesetzt. |
3 |
SearchProfile-Remove-Button |
Das aktuelle Search Profile wird gelöscht. Die Löschung erfolgt erst nach dem im Verifikationsdialog "Möchten Sie wirklich löschen?" mit "Ja" selektiert wurde. |
4 |
SearchProfile-Name-Textfield |
Enthält den Namen des aktuell bearbeiteten Search Profiles. Zum Kopieren von SearchProfiles kann hier bei einem existierenden SearchProfil ein neuer Name eingetragen werden. Das Speichern erzeugt einen neuen Eintrag. |
5 |
SearchProfile-IndexProfile-Selection-DropDown |
Eine Suche basiert immer auf einem Index Profile und kann im Suchergebnis nur die Felder enthalten, die in einem Index Profile definiert sind. Mit diesem DropDown wird das Index Profile verknüpft. Es kann mehrere SuchProfile geben, die das gleiche Index Profile benutzen. |
6 |
SearchProfile-Template-Selection-Drop-Down |
Um Suchergebnisse über ein Template auszuspielen (statt im Standard JSON Format zb direkt HTML), muss dem Suchergebnis ein Template zugeordnet sein. Mit diesem DropDown erfolgt die Template-Zuordnung zum Search Profile. Zusätzlich werden über ein Template die Highlight-Tags definiert. Diese werden auch in der Standard-JSON Ausspielung verwendet. |
7 |
SearchProfile-DefaultOperator-Selection-Drop-Down |
Besteht ein Suchstring aus mehereren Worten, so kann hier selektiert werden, ob alle Worte in einem Suchergebnis enthalten sein müssen (AND) oder ein Wort des Suchstrings für einen Treffer genügt (OR). |
8 |
SearchProfile-MultimatchType-Selection-Drop-Down |
Mit diesem Drop Down wird die Methode definiert, nach der ein Suchergebnis ermittelt wird. Siehe auch Detail-Dokumentation. |
9 |
SearchProfile-Suggest-CheckBox |
Mit dieser Option wird eingeschaltet, ob die Vorschlags-Funktion ("Meinten Sie") ausgegeben werden soll. |
10 |
SearchProfile-Explain-CheckBox |
Mit dieser Option wird eingeschaltet, ob die Explain-Funktion ausgegeben werden soll. |
11 |
SearchProfile-Highlight-CheckBox |
Mit dieser Option wird eingeschaltet, ob die Highlighting-Funktion ausgegeben werden soll. Wenn |
12 |
SearchProfile-PageSize-numTextField |
In diesem numerischen Eingabefeld wird die Anzahl, der auf einer Seite auszugebenden Suchergebnisse spezifiziert. |
13 |
SearchProfile-TypeaheadSize-numTextField |
In diesem numerischen Eingabefeld wird die max. Anzahl, der auszugebenden Typeahead Worte spezifiziert. |
14 |
SearchProfile-ndxField-Selection-DropDown |
Mit dieser Auswahl wird ein indexiertes Feld spezifiziert, das im Suchergebnis mit ausgegeben werden soll. |
15 |
SearchProfile-Einstellungen-tblColumn |
Diese Tabellenspalte enthält alle Einstellungen, die bei diesen Feld-Type möglich sein. |
16 |
SearchProfile-Remove-Field-Button |
Mit diesem Button kann das in der Zeile befindliche indexierte Feld aus dem Search Profile gelöscht werden. |
17 |
SearchProfile-Add-Field-Button |
Mit diesem Button kann ein weiteres indexiertes Feld dem Search Profile zugeordnet werden. |
18 |
SerachProfile-ndxField-Score-Button |
Mit diesem Button öffnet sich eine DialogBox, in die eine Scores-Konfiguration zugeordnet und konfiguriert werden kann um den Score der gefundenen Dokumente zu manipulieren. |
19 |
SearchProfile-ndxField-Facet-Textfield |
CheckBox mit der das im SearchProfile-ndxField-Selection-DropDown ausgesuchte Feld als Facette im Suchergebnis ausgegeben werden soll. Das Textfeld dahinter beschreibt, wie viele Facetten dieses Feldes maximal ausgegeben werden dürfen. Das ist ein Wert zwischen 1-100. |
20 |
SearchProfile-not_searchable-Field |
Ein not_searchable Feld, dass im SearchProfile angegeben ist, wird im SearchResult ausgegeben. Es kann nicht konfiguriert werden. |
21 |
SearchProfile-fulltextsearch-CheckBox |
Mit diesem boolschen Selector wird spezifiziert, ob dieses Feld für die Volltextsuche genutzt werden soll. |
22 |
SearchProfile-prefixsearch-CheckBox |
Mit diesem boolschen Selector wird spezifiziert, ob dieses Feld für die Prefixsuche genutzt werden soll. Unvollständige Wörter (Prefix eines Worts) finden. |
23 |
SearchProfile-ndxField-Typeahead-CheckBox |
Mit diesem boolschen Selector wird spezifiziert, ob dieses Feld für die Typeahead Vorschläge genutzt werden soll. Die Wörter dieses Felds sollen als Typeahead Vorschläge benutzt werden. |
24 |
SearchProfile-ndxField-Boost-numTextField |
Enthält einen Boost-Value, der das ausgesuchte Feld im SearchProfile-ndxField-Selection-DropDown im errechneten Scoring höher bewertet. Wenn eines der Suchworte in diesem Feld gefunden wurde, dann wird der Score des gefundenen Dokuments um den Boost Faktor erhöht. |
25 |
SearchProfile-hide-CheckBox |
Mit diesem boolschen Selector wird spezifiziert, ob dieses Feld im SearchResult ausgegeben werden soll. Zum Beispiel können Volltext-Felder sehr umfangreich sein und werden nicht immer im Ergebnis gebraucht. So kann die Größe des Suchresultats reduziert werden. |
26 |
SearchProfile-SortField-Selection-DropDown |
In dieser Auswahl werden Felder spezifiziert, über das die Sortierung des Suchergebnisses erfolgen soll.
In der Standardsortierung mit |
27 |
SearchProfile-SortDirection-Selection-DropDown |
In dieser Auswahl wird die Sortierreihenfolge (aufsteigend=ASC) oder (absteigend=DSC) spezifiziert. |
28 |
SearchProfile-Filters-Filter-TextField |
In diesem Text-Feld kann ein weiterer frei formulierbarer Filter eingetragen werden:
Weitere technische Details dazu: Filter |
29 |
SearchProfile-Filters-Remove-Filter-Button |
Mit diesem Button kann der frei formulierbare Filter in der Zeile des Buttons gelöscht werden. |
30 |
SearchProfile-Filters-Add-Filter-Button |
Mit diesem Button kann ein weiterer frei formulierbarer Filter hinzugefügt werden. |
31 |
SearchProfile-URL-Include-pattern-Textfield |
In diesem mehrzeiligen Textfeld kann in jeder Zeile ein Dokumenten-Pfad spezifiziert werden, der in die Suche explizit aufgenommen werden soll.
Es muss ein Regulärer Ausdruck sein.
Z.B.: |
32 |
SearchProfile-URL-Exclude-pattern-Textfield |
In diesem mehrzeiligen Textfeld kann in jeder Zeile ein Dokumenten-Pfad spezifiziert werden, der in die Suche explizit ausgeschlossen werden soll.
Es muss ein Regulärer Ausdruck sein.
Z.B.: |
33 |
SearchProfile-Custom-Payload |
In diesem mehrzeiligen Textfeld kann beliebiger kundenspezifischer JSON Code eingefügt werden.
Dieser kann für die Entwicklung von Frontends, ohne die Transformation über die Templates, auf Basis des JSON SearchResults genutzt werden.
Neben Visualisierungsangaben können hier z.B. ein Mapping der technischen Feld- und Facettenbezeichnungen zu nutzerfreundlichen Bezeichnungen, auch mehrsprachig, hinterlegt werden.
Der Payload muss in einem validen Json Format sein und wird im SearchResults über den Key |
34 |
SearchProfile-Save-Button |
Mit diesem Button wird das aktuell editierte Search Profile unter dem Namen im SearchProfile-Name-Textfield gespeichert. |
4.5.3. Technische Dokumentation
Die Dokumentation der Schnittstellen finden sie unter Suchprofile.
4.5.4. Scores-Konfiguration
Einleitung
Scores bieten die Möglichkeit, die von der Suche zurückgegebenen Gesamtscores der Dokumente zu manipulieren und so die Reihenfolge der Dokumente im Suchergebnis zu verändern ("weiche Sortierung"). Der Gesamtscore eines Dokuments basiert bei der CSA darauf, wie stark die eingegebene Suchanfrage mit dem Dokument übereinstimmt. Die Dokumente mit den besten Übereinstimmungen und den damit höchsten Gesamtscores werden im Suchergebnis an den ersten Stellen stehen.
Mit dem Parameter {sc|score} lassen sich die Gesamtsscores der
Dokumente manupulieren. Dafür werden aus vorhanden Feldern des
Dokuments und mathematischen Funktionen ein oder mehrere Teilscores
berechnet und diese zum ursprünglichen Gesamtscore hinzu
multipliziert. So können Dokumente, die z.B.
-
oft angesehen wurden, gute Bewertungen haben
-
jünger sind
-
Werte in einem Bestimmten Bereich haben (zB: empfohlen für die Altersgruppe 20-40, oder Einkommen zwischen 20.000 - 40.000, oder um ein bestimmtest Datum herum erstellt wurden)
-
in der Nähe von einem bestimmten Ort (Geoinformationen) sind
-
Dokumente, die bestimmte Worte enthalten (Search Promotion)
ihren Score verbessern und im Suchergebnis weiter vorne erscheinen.
Benutzeroberfläche Field Value Factor
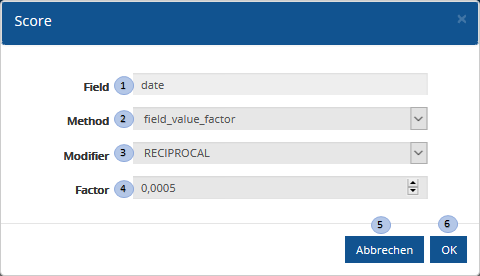
| Nr. | Eingabe-Element | Funktion |
|---|---|---|
1 |
SearchProfile-Score-FieldName |
Enthält das Feld für das ein Score definiert werden soll |
2 |
SearchProfile-Score-Method-Selection |
Ermöglicht die Auswahl der Scoring Methode Field Value Factor, Decay |
3 |
SearchProfile-Score-FVF-Modifier |
Ermöglicht die Auswahl einer mathematischen Funktion zur Berechnung des Field Value Factors. |
4 |
SearchProfile-Score-FVF-Factor |
Ermöglicht die Eingabe eines Factors auf dem die ausgewählte Funktion einen Field Value Factor errechnet. |
5 |
SearchProfile-Score-Cancel-Button |
Bricht die Konfiguration ohne Speicherung ab und schließt den Dialog. |
6 |
SearchProfile-Score-OK-Button |
Speichert die Konfiguration und schließt den Dialog |
Folgende FVF-Modifier können im Eingabeelement SearchProfile-Score-FVF-Modifier ausgewählt werden.
| FVF-Modifier | Meaning |
|---|---|
|
Do not apply any multiplier to the field value |
|
Take the common logarithm of the field value |
|
Add 1 to the field value and take the common logarithm |
|
Add 2 to the field value and take the common logarithm |
|
Take the natural logarithm of the field value |
|
Add 1 to the field value and take the natural logarithm |
|
Add 2 to the field value and take the natural logarithm |
|
Square the field value (multiply it by itself) |
|
Take the square root of the field value |
|
Reciprocate the field value, same as |
Benutzeroberfläche Decay
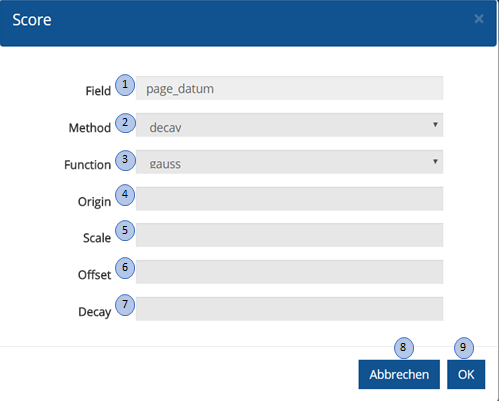
| Nr. | Eingabe-Element | Funktion |
|---|---|---|
1 |
SearchProfile-Score-FieldName |
Enthält das Feld für das ein Score definiert werden soll |
2 |
SearchProfile-Score-Method-Selection |
Ermöglicht die Auswahl der Scoring Methode (Field Value Factor, Decay |
3 |
SearchProfile-Score-Decay-Modifier |
Ermöglicht die Auswahl einer mathematischen Funktion zur Berechnung des Scores. |
4 |
SearchProfile-Score-Decay-Origin |
Eingabefeld für den Faktor Origin.
Siehe Decay |
5 |
SearchProfile-Score-Decay-Scale |
Eingabefeld für den Faktor Scale.
Siehe Decay |
6 |
SearchProfile-Score-Decay-Offset |
Eingabefeld für den Faktor Offset.
Siehe Decay |
7 |
SearchProfile-Score-Decay-Value |
Eingabefeld für den Faktor Decay,
Siehe Decay |
8 |
SearchProfile-Score-Cancel-Button |
Bricht die Konfiguration ohne Speicherung ab und schließt den Dialog. |
9 |
SearchProfile-Score-OK-Button |
Speichert die Konfiguration und schließt den Dialog |
Benutzeroberfläche Search Promotion
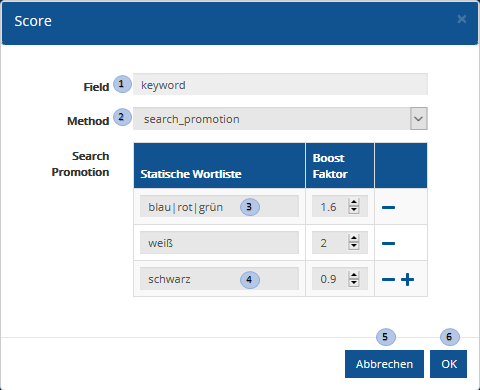
| Nr. | Eingabe-Element | Funktion |
|---|---|---|
1 |
SearchProfile-Score-FieldName |
Enthält das Feld für das ein Score definiert werden soll.
Es werden die Typen text, keyword und bool unterstützt.
Bei bool sind im Textfield nur Kombinationen aus true, false oder |
2 |
SearchProfile-Score-Method-Selection |
Ermöglicht die Auswahl der Scoring Methode Field Value Factor, Decay |
3 |
SearchProfile-Score-FVF-Textfield |
Beispiel für mehrere Wörter mit dem gleichen Boost Faktor.
Zusätzlich kann der Platzhalter |
4 |
SearchProfile-Score-FVF-Factor |
Beispiel für ein Wort, mit einem Boost Faktor <1. Bei allen Dokumenten, die dieses Wort enthalten, wird der Score leicht verringert. |
5 |
SearchProfile-Score-Cancel-Button |
Bricht die Konfiguration ohne Speicherung ab und schließt den Dialog. |
6 |
SearchProfile-Score-OK-Button |
Speichert die Konfiguration und schließt den Dialog |
Schnittstelle/Endpoint-Bescheibung
-
Als Endpoint wird der search-endpoint benutzt. Er ist in der Spezifikation des Search API beschrieben. score ist ein Parameter des search-endpoints.
-
Validierung:
-
jede Score Funktion muss aus einem functionScoreName und einer Menge von Argumenten bestehen, die mit ':' voneinander getrennt sind
-
functionScoreName und die Argumente sind mit einem Doppelpunkt voneinander getrennt
-
es dürfen nur Feldnamen mit Typen benutzt werden, die für eine bestimmte functionScore-Methode zugelassen sind (siehe Tabelle)
-
die Argumente sind für jede functionScore-Methode anders, die Reihenfolge und die Datentypen müssen eingehalten werden
-
| Parameter-Key | Value | Default | Mandatory | Beschreibung |
|---|---|---|---|---|
score|sc |
score=functionScoreName:arg1:arg2:.. |
- |
- |
Für alle Dokumente im Suchergebnis wird ein zusätzlicher Scorewert berechnet und mit dem Gesamtscore multipliziert. |
| Argumente | erlaubte Typen | Beschreibung | Beispiele |
|---|---|---|---|
fieldname |
bool, num_double, num_long, date |
Beschreibt den Feldnamen im indexierten Dokumente unterhalb von fields, deren Wert für die Berechnung benutzt werden soll. Es dürfen nur Fields mit numerischen Werten, bool ist 0 oder 1 und date als Zeitstempel in ms genutzt werden. |
|
fieldFunction |
none (keine Funktion benutzen), log, log1p, log2p, ln, ln1p, ln2p (Logarithmen), square (Quadrat), sqrt (Wurzel), reciprocal (Kehrwert) |
Alle Logarithmusfunktionen die im Namen eine Zahl enthalten: Addieren
diese Zahl zum Wert im Dokumente, der in fieldname steht und erst danach
wird der Logarithmusfunktion berechnet.
Alle Wurzel-, Quadrat- und Logarithmusfunktionen sind steigende
Funktionen. Je größer der Wert \(x\) desto höher ist das Ergebnis.
Die Quadratfunktion steigt am schnellsten, vielleicht zu schnell für
einige Anwendungsfälle.
Die Wurzelfunktion steigt langsamer und die Logarithmen steigen sehr
langsam - bei großen Zahlen für x ist das Ergebnis fast das gleiche.
Der Kehrwert ist im positiven Bereich eine fallende Funktion. Die
Ergebnisse werden groß, falls das x möglichst klein ist. |
|
fieldFactor |
float |
Faktor, mit dem der Wert im Dokument, der in fieldname steht, mulipliziert wird |
|
missing |
float |
Faktor, mit dem der Wert im Dokument, der in fieldname steht, mulipliziert wird |
| Argumente | erlaubte Typen | Beschreibung | Beispiele |
|---|---|---|---|
fieldName |
num_double, num_long, date |
Beschreibt den Feldnamen im indexierten Dokumente unterhalb von fields, deren Wert für die Berechnung benutzt werden soll. |
|
decayFunction |
gauss, linear, exp |
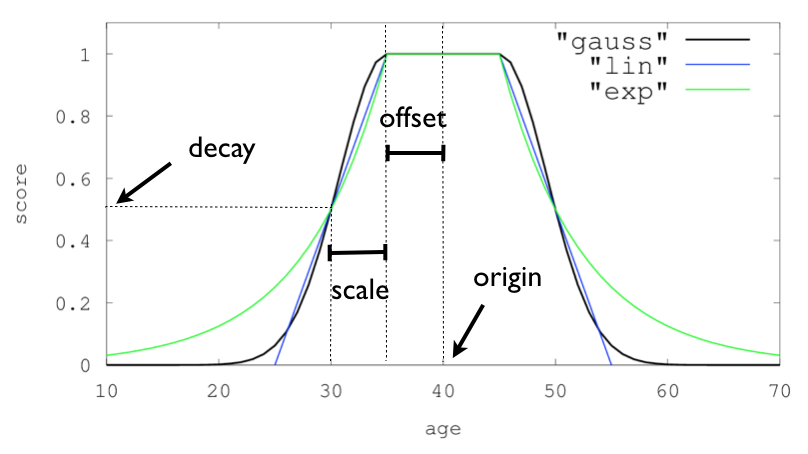
Alle drei Funktionen haben ein ähnliches Aussehen. Sie haben einen Ursprung (origin) der den höchsten Score von 1.0 zurück gibt. Dann kann mit scale angegeben werden, wieviele Werte (x-Achse) um den Ursprung herum auch sehr wichtig sein sollen und mit decay wird angegeben, welche Scorewerte in diesem wichtigen Bereich zurückgegeben werden sollen, die Scorewerte sollen mindestens decay groß sein oder größer, maximal 1.0. Die drei Funktionen unterscheiden sich vorallem darin, wie die Scores von Dokumenten berechnet werden, die sich ausserhalb des wichtigen Bereichs befinden. Linear gibt für Dokumente die 1/decay mal so weit vom wichtigen Bereich entfernt sind, 0 zurück. Die anderen beiden Funktionen schwächen die Scorewerte schneller (gauss) oder langsamer (exp) ab, lassen sie aber nicht so schnell 0 werden.
|
|
origin |
numerischer Wert Datum oder "now", auch eifnache Datumsberechnung "now-1h" Geopoints |
Der Ausgangspunkt/Ursprung für die Distanzberechnung. Hier kann gerade beim Datum auch der Wert now angegeben werden, was Distanzberechnungen zum aktuellen Zeitpunkt ermöglicht. |
|
scale |
numerischer Wert, Datum: Zahl + Einheit (1h, 23d), ohne Einheit sind es Milisekunden Geopoints: Zahl + Einheit (1km, 12m), ohne Einheit wird Meter (m) benutzt |
Wert, an dem die Distanz zum Ursprung größer wird, als der priorisierte Bereich. Einheiten für Datum: d, h, m, s, ms, micros, nanos. |
|
offset |
gleiche Typen wie scale |
Wert, der um den Ursprung herum den Höchstscore von 1.0 erhalten soll. |
|
decay |
float 0-0.9999 |
Wert, der zurückgegeben werden soll, wenn genau scale erreicht ist. |
| Argumente | erlaubte Typen | Beschreibung | Beispiele |
|---|---|---|---|
fieldname |
keyword, text |
Beschreibt den Feldnamen im indexierten Dokument unterhalb von fields, in dem die Search Promotion Wörter enthalten sein sollten, um den Score zu manipulieren. |
|
Statische Wortliste |
Wortliste, mehrere Wörter für den gleichen Boost mit |
Die Wortliste wird beim Type=keyword direkt übernommen. Wenn das Feld vom Type=text ist, dann werden die Wörter der Wortlisten mit dem gleichen Analyser analysiert, im Field Definition Mapping angegeben. |
|
Boost Faktor |
float |
Faktor, mit dem der Score des Dokuments mulipliziert werden soll, falls in fieldname ein Treffer der Wortliste enthalten ist. |
Einrichtung und Bedienung
Mit der Angabe des score-Parameters am search-Endpoint oder durch die Konfiguration in der Search-Profiles-Konfiguration ist die Score-Manipulation eingerichtet.
Algorithmus / Funktionale Abfolge / Ablaufprozess
Der Gesamtscore eines Dokumentes wird nachträglich verändert mit der Funktion und den Werten der angegebenen Funktion.
4.6. Templates-Konfiguration
CSA-Suchergebnisse werden als HTML-Snippets zurückgegeben. Die HTML-Snippet-Aufbereitung der Suchergebnis-Daten erfolgt über die Integration der Semantic Templating-Engine handlebars. Darüber kann die Ausprägung des HTML-Codes festgelegt werden und die Suchergebnis-Daten in das HTML substituiert werden. In Such-Profiles, die mit denen Templates verknüpft sind, sind die Datenfelder des Suchergebnisses als auch auch weitere funktionale Ausprägungen (Suggestion, Typeahead, Explanations, etc.) definiert.
Die in einen Template definierten Highlight-Tags werden auch bei der CSA Result Json Ausgabe verwendet.
4.6.1. Benutzeroberfläche
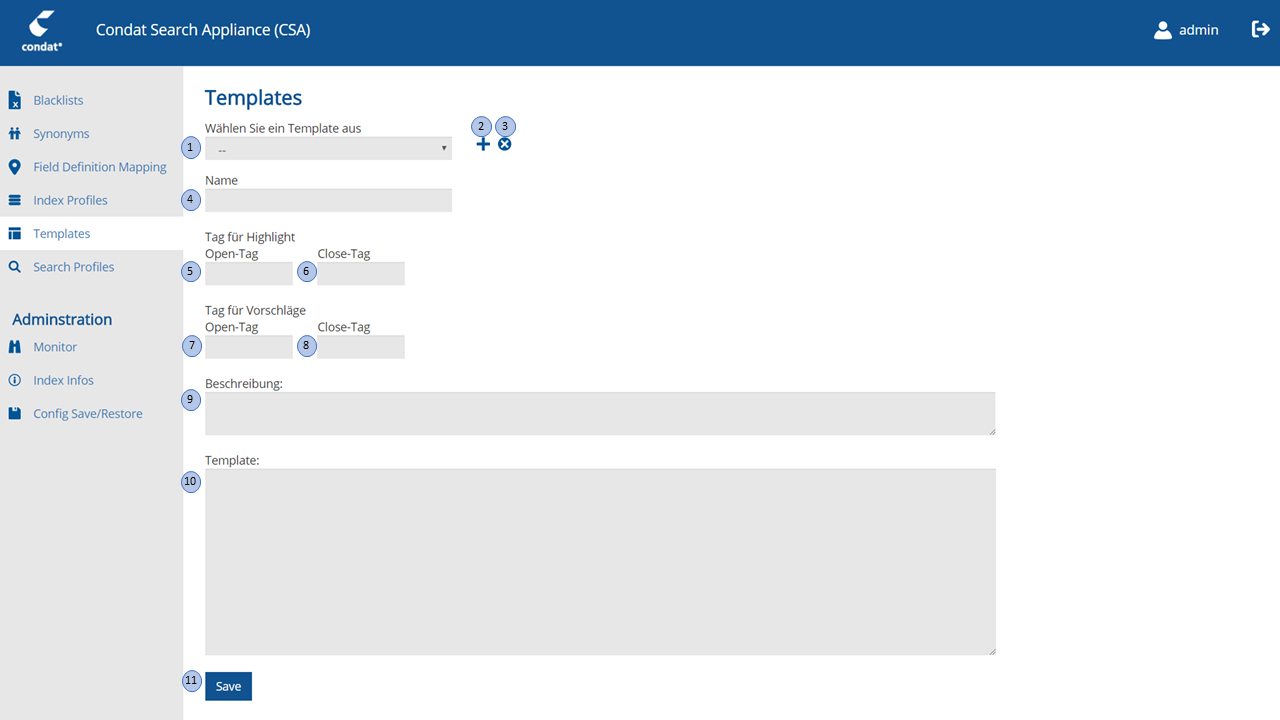
| Nr. | Eingabe-Element | Funktion |
|---|---|---|
1 |
Template-Selection-Drop-Down |
Ermöglicht die Auswahl eines zu editierenden Templates aus einer Liste der gespeicherten Templates. Mit der Auswahl eines Template aus der Liste wird das ausgewählte Template geladen. |
2 |
Add-Template-Button |
Button mit dem ein neues Template hinzugefügt werden kann. Mit Auswahl des Buttons wird die Editiermaske zurückgesetzt. |
3 |
Remove-Template-Button |
Das aktuelle Template wird gelöscht. Die Löschung erfolgt erst nach dem im Verifikationsdialog "Möchten Sie die Template löschen?" mit "Ja" selektiert wurde. |
4 |
Template-Name-Textfield |
Feld enthält den Namen des aktuell bearbeiteten Templates. |
5 |
Highlight-OpenTag-Textfield |
Öffnender HTML-Tag mit dem hervorgehobener Text durch Highlighting im HTML-Code ausgespielt werden soll. (z.B. <HIGHLIGHT> |
6 |
Highlight-CloseTag-Textfield |
Schliessender HTML-Tag mit dem hervorgehobener Text durch Highlighting im HTML-Code ausgespielt werden soll. </HIGHLIGHT> |
7 |
Suggest-OpenTag-Textfield |
Öffnender HTML-Tag mit dem Vorschläge (Suggestions) im HTML-Code ausgespielt werden soll. (z.B. <SUGGEST> |
8 |
Suggest-CloseTag-Textfield |
Schliessender HTML-Tag mit dem Vorschläge (Suggestions) im HTML-Code ausgespielt werden soll. </SUGGEST> |
9 |
Template-Description-Multitextfield |
Mehrzeiliges Textfeld mit dem das Template freisprachlich beschrieben werden kann. |
10 |
Template-Code-Multilinetextfield |
Enthält die Implementierung des Templates. Mehrzeiliges Textfeld in das der HTML/Handlebar-Code des Template eingefügt wird. |
11 |
Template-Save-Button |
Button zum Speichern des aktuell in Bearbeitung befindlichen Templates. |
4.6.2. Allgemeines zur Template-Entwicklung
Um die Suchergebnisse aus den Search-Profiles über ein Template darzustellen, müssen die Daten der Suchergebnisse über Record-Variablen ausgelesen werden.
SearchResults
Suchergebnisse werden je nach Konfiguration des SeachProfiles immer in der Variablen searchResults vom Type SearchResults zurückgegeben.
SearchResults hat folgende Attribute:
| Attribut | Datentyp | Erklärung |
|---|---|---|
results |
List<Result> |
Liste mit den Suchergebnissen des Typs `Templates-Konfiguration#Result. Die Anzahl der Suchergebnisse ergibt sich aus der Angabe der Seitenlänge die im Suchergebnise ` |
suggestions |
List<Suggestion> |
Liste mit Suggestions |
totalResultsCount |
Long Integer |
Anzahl der gefundenen Suchergebnisse |
facets |
Facets |
Facetten die aus dem Sichergebnis herausextrahiert wurden. |
first |
String |
Link auf die erste Seite der Suchergebnis-Seiten |
last |
String |
Link auf die letzte Seite der Suchergebnis-Seiten |
prev |
String |
Link auf die vorherige Seite der Suchergebnis-Seiten |
next |
String |
Link auf die nächste Seite der Suchergebnis-Seiten |
self |
String |
Link auf die aktuelle Seite der Suchergebnis-Seiten |
Ein Suchergebnis ist vom Type Result mit folgenden Attributen:
| Attribut | Datentyp | Erklärung |
|---|---|---|
|
|
Der von Elasticsearch errechnete Score eines Ergebnisses |
|
|
Die ID eines Suchergebnisses |
|
|
Ein URL mit dem Taget-Dokument des Ergebnisses |
|
|
Alle durch Highlighting hervorzuhebenden Worte innerhalb des Suchergebnisses |
|
|
Zeigt auf die Felder des Suchergebnisses. Enthält alle Felder die im SearchProfile angegeben wurden. Die versteckten Felder (hide) werden nicht übergeben. Die Felder werden sortiert zurückgegeben. |
Suggestions enthält jeweils eine Liste von Objekten des
Datentyps Suggestion mit folgenden Attributen:
| Attribut | Datentyp | Erklärung |
|---|---|---|
|
|
Der Text eines Vorschlags. |
|
|
Der Text zusammen mit dem Markup für das Highlighting |
|
|
Der Score des Vorschlags |
fields enthält alle Felder, die im Search-Profile angegeben sind, so dass diese wie folgt angesprochen werden können:| Attribut | Datentyp | Erklärung |
|---|---|---|
<Feldname> |
Codebeispiel Suchergebnisse iterieren
Für die Ausgabe der Suchergebnisse wird über die searchResults iteriert und es werden die Einzelergebnisse behandelt:
<!-- iteriere über alle Ergebnisse -->
{{#each searchResults.results}}
{{#if fields}}
<p>
<!-- alle verfügbare Felder iterieren -->
{{#each fields}}
{{@key}}: {{this}}
{{/each}}
</p>
{{/if}}
<!-- alle verfügbare highlighted-Felder iterieren -->
{{#if highlighted}}
<p>
{{#each highlighted}}
{{@key}}: {{{escapeExcludeHighlightingTag this}}}
{{/each}}
</p>
{{/if}}
{{/each}}Codebeispiel: Paginierung
Paginierung
<nav class="csa-pagination">
{{#if searchResults.prev}} <!-- ob prev-page vorhanden -->
<a class="page_link" href="{{firstUrl}}"><<</a>
<!-- firstUrl: CSA-Hilfmethode: Link zur ersten Suchergebnis-Seite -->
<a class="page_link" href="{{prevUrl}}"><</a>
<!-- firstUrl: CSA-Hilfmethode: Link zur vorherigen Suchergebnis-Seite -->
{{/if}}
<a class="page_link current-page" href="{{pageUrl 0}}">{{pageNr 0}} </a>
<!-- pageUrl: CSA-Hilfmethode: Link zur aktuellen Suchergebnis-Seite -->
{{#hasPage 1}} <!-- ob die Seite = aktuelle Seite + 1 vorhanden -->
<a class="page_link" href="{{pageUrl 1}}">{{pageNr 1}}</a>
<!-- pageUrl: CSA-Hilfmethode: Link zur Seite = aktuelle + 1-->
{{/hasPage }}
{{#hasPage 2}} <!-- ob die Seite = aktuelle Seite + 2 vorhanden -->
<a class="page_link" href="{{pageUrl 2}}">{{pageNr 2}}</a>
<!-- pageUrl: CSA-Hilfmethode: Link zur Seite = aktuelle + 2-->
{{/hasPage }}
{{#if searchResults.next}}
<a class="page_link" href="{{nextUrl}}">></a>
<!-- nextUrl: CSA-Hilfmethode: Link zur nächsten Suchergebnis-Seite -->
<a class="page_link" href="{{lastUrl}}">>></a>
<!-- lastUrl: CSA-Hilfmethode: Link zur letzten Suchergebnis-Seite -->
{{/if}}
</nav>4.6.3. Technische Dokumentation
Die Dokumentation der Schnittstellen finden sie unter Templates.
4.7. Blacklist-Konfiguration
Blacklisten erlauben den Ausschluß von unerwünschten Worten beim Indexieren von Dokument-Texten. Für Suchbegriffe die in Blacklisten gelistet sind werden keine Suchergebnisse erzeugt.
4.7.1. Benutzerobefläche
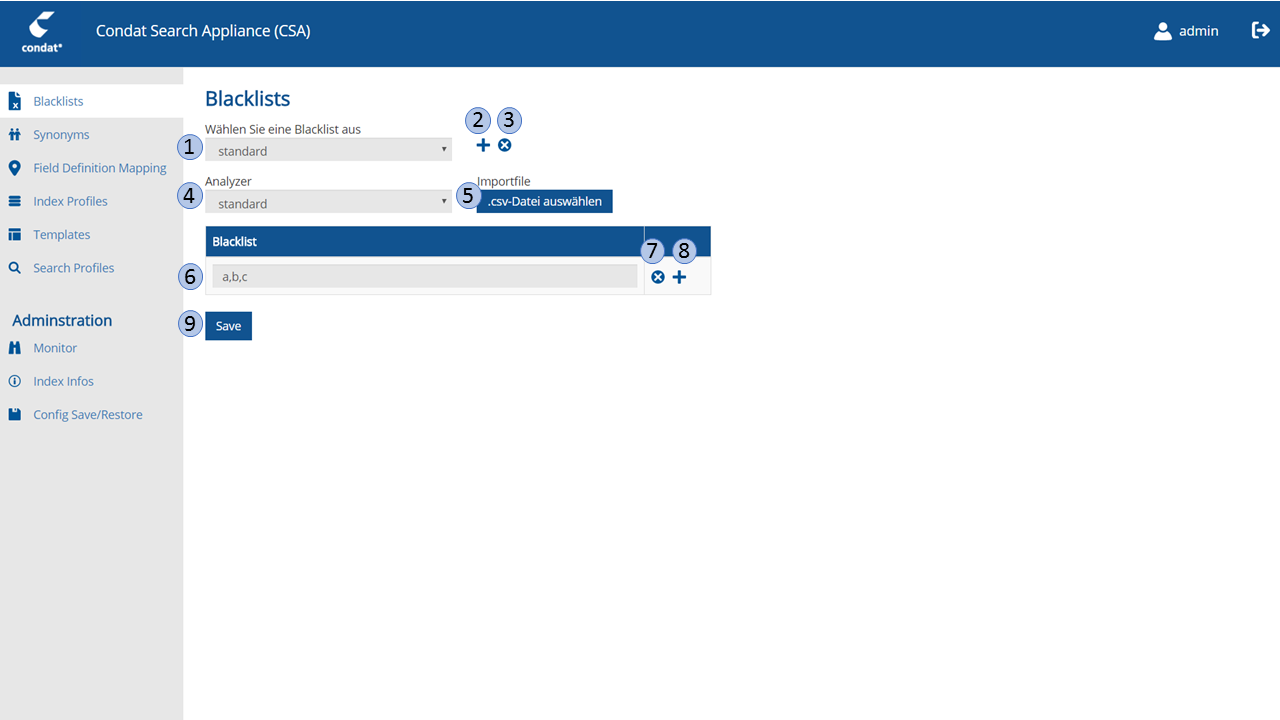
4.7.2. Eingabe-Elemente der Blacklist-Konfiguration
| Nr. | Eingabe-Element | Funktion |
|---|---|---|
1 |
Blacklist-Selection-Drop-Down |
Ermöglicht die Auswahl einer zu editierenden Blacklist aus einer Liste der gespeicherten Blacklists. Mit der Auswahl einer Blacklist aus der Liste wird die ausgewählte Blacklist geladen. |
2 |
Add-Blacklist-Button |
Button mit dem zu einem Analyzer eine Blacklist hinzugefügt werden kann. Mit Auswahl des Buttons wird die Editiermaske zurückgesetzt. |
3 |
Remove-Blacklist-Button |
Die aktuelle Blacklist wird gelöscht. Die Löschung erfolgt erst nach dem im Verifikationsdialog "Möchten Sie die Blacklist löschen?" mit "Ja" selektiert wurde. |
4 |
Analyzer-Selection-Drop-Down |
Auswahl des Analyzers, dem die Blacklist der auszuschließenden Worte zugeordnet ist. Der ausgewählte Name des Analyzers entspricht dem Namen der Blacklist im Blacklist-Selection-Drop-Down. |
5 |
Blacklist-CSV-File-Import-Button |
Öffnet einen Dateidialog mit dem eine Text-Datei ausgewählt werden kann. In der Datei müssen die zu importierenden Worte mit Zeilenumbruch getrennt sein. |
6 |
Blacklisted-Word-Text-Field |
Text-Eingabe-Feld in das ein auszuschliessendes Wort eingeragen wird. |
7 |
Add-Blacklisted-Word-Button |
Erzeugt ein weiteres Blacklisted-Word-Text-Field. |
8 |
Delete-Blacklisted-Word |
Löscht das Blacklisted-Word-Text-Field. |
9 |
Save-Blacklist-Button |
Speichert die Blacklist unter dem Namen des ausgewählten Analyzers. |
4.7.3. Technische Dokumentation
Die Dokumentation der Schnittstellen finden sie unter [Blacklists und Synonyms].
4.8. Synonym-Listen-Konfiguration
Synonymlisten erlauben die Definition von synonymen Worten beim Indexieren von Dokument-Texten. Bei der Erstellung von Suchergebnissen werden die Synonyme hinzugezogen, so das neben den eingegebenen Suchbegriffen auch die Suchergebnisse der Suchbegriff-Synonyme enthalten sind.
4.8.1. Synonymlisten-Konfiguration-GUI
Benutzeroberfläche

Eingabe-Elemente der Synonymlist-Konfiguration
| Nr. | Eingabe-Element | Funktion |
|---|---|---|
1 |
Synonymlist-Selection-Drop-Down |
Ermöglicht die Auswahl einer zu editierenden Synonymlist aus einer Liste der gespeicherten Synonymlists. Mit der Auswahl einer Synonymlist aus der Liste wird die ausgewählte Synonymlist geladen. |
2 |
Add-Synonymlist-Button |
Button mit dem zu einem Analyzer eine Synonymlist hinzugefügt werden kann. Mit Auswahl des Buttons wird die Editiermaske zurückgesetzt. |
3 |
Remove-Synonymlist-Button |
Die aktuelle Synonymlist wird gelöscht. Die Löschung erfolgt erst nach dem im Verifikationsdialog "Möchten Sie die Synonymlist löschen?" mit "Ja" selektiert wurde. |
4 |
Analyzer-Selection-Drop-Down |
Auswahl des Analyzers dem die Synonymlist der auszuschließenden Worte zugeordnet ist. Der ausgewählte Name des Analyzers entspricht dem Namen der Synonymlist im Synonymlist-Selection-Drop-Down. |
5 |
Synonymlist-CSV-File-Import-Button |
Öffnet einen Dateidialog mit dem eine Text-Datei ausgewählt werden kann. In der Datei müssen die zu importierenden Worte mit Zeilenumbruch getrennt sein. |
6 |
Synonym-Word-Text-Field |
Text-Eingabe-Feld in das ein Synonym-Word eingetragen wird. |
7 |
Add-Synonymlisted-Word-Button |
Erzeugt ein weiteres Synonym-Word-Text-Field. |
8 |
Delete-Synonymlisted-Word |
Löscht das Synonym-Word-Text-Field. |
9 |
Save-Synonymlist |
Speichert die Synonymlist unter dem Namen des ausgewählten Analyzers |
4.8.2. Technische Dokumentation
Die Dokumentation der Schnittstellen finden sie unter [Blacklists und Synonyms].
4.9. Crawler-Konfguration
4.9.1. Einleitung
Mit der Crawler-Funktion wird der Content einer Webstite analysiert. Mit einem Crawler können Websites über ihre URLs abgerufen werden, die Seiten analysiert und indexiert werden.
Ein Crawler
-
durchsucht bei der Content-Analyse alle URL-Links, die auf einer Seite gefunden werden,
-
lädt diese und
-
analysiert diese.
Dieser rekrsive Vorgang erfolgt solange, bis alle Seiten einer Website analysiert sind und im entsprechenden Index erfasst sind.
Ein Crawler bezieht sich auf ein zugewiesenes Index-Profil. Ein Index-Profil enthält die Konfiguration für die Content-Analyse und den Ziel-Index .
Die Crawler-Konfiguration enthält die Angaben, welche Bereiche des Content-Netzes (in einer Website) analysiert werden.
4.9.2. Benutzeroberfläche
| Nr | Eingabeelement | Funktion | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
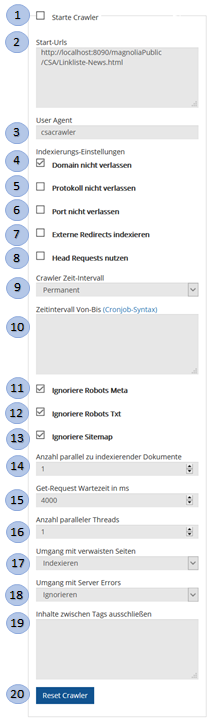
|
1 |
Crawler-Activate-CheckBox |
Mit dieser Checkbox wird der Crawler aktiviert (Checkbox on) und
deaktiviert (Checkbox off). Der gewünschte Aktivierungszustand wird
ausgelöst, nachdem das Crawler-Profil gespeichert wurde. Der Crawler kann über den ResetCrawler-Button zurückgesetzt werden. |
|||||||||||||
2 |
StartURLs-MultilineTextField |
In desem Feld werden die zu
indexierenden Wurzel-URLs angegeben, die vom Crawler indexiert werden
sollen. |
||||||||||||||
3 |
User-Agent-TextField |
In diesem Feld kann der Name eines User Agents angegeben werden, um den Crawler bei seinen Anfragen an die Website von normalen Useranfragen unterscheiden zu können. |
||||||||||||||
4 |
IgnoreExternalDomains-CheckBox |
Mit dieser Checkbox wird eingestellt, dass der Crawler Links ignoriert, die außerhalb der Domains der Start-URLs liegen. |
||||||||||||||
5 |
IgnoreExternalProtocols-CheckBox |
Mit dieser Checkbox wird eingestellt, dass der Crawler Links ignoriert, die andere Protokoll enthalten als in den Start-URLs. |
||||||||||||||
6 |
IgnoreExternalPorts-CheckBox |
Mit dieser Checkbox wird eingestellt, dass der Crawler Links ignoriert, die andere Port-Nummern enthalten als in den Start-URLs. |
||||||||||||||
7 |
FollowExternalRedirects-CheckBox |
Mit dieser Checkbox wird eingestellt, dass der Crawler den Inhalt eines Links crawlen soll, der auf eine fremde Website führt, wenn dieser Link als ein interner Link gecrawlt wurde, aber beim Lesen durch ein 30x Status zu einem Redirekt führt. Die URLs der fremden Website werden nicht weiterverfolgt. |
||||||||||||||
8 |
UseHeadRequests-CheckBox |
Mit dieser Checkbox wird eingestellt, dass der Crawler zuerst einen Head Request an die Website schickt um zu erfahren, ob der Inhalt der URL sich geändert hat. Vor dem Aktivieren bitte prüfen, ob Head-Requests auf der Website erreichbar sind und die Informationen im Head-Request auch wirklich folgende Anforderung erfüllt: Eines oder mehrere der HTTP header muss im Response des Head-Requests enthalten sein: "Last-Modified", "ETag", "Content-Length", "Content-MD5" und diese Information ändert sich genau dann, wenn die gleiche URL bei einem GET-Request auch einen veränderten Inhalt liefern würde. |
||||||||||||||
9 |
CrawlerTimeIntervall-DropDown |
In diesem Selektionsfeld kann der Modus für die Zeitintervall-Steuerung des Crawlers eingestellt werden. Die möglichen Werte sind:
|
||||||||||||||
10 |
CrawlerTimeSetting-MultilineTextField |
In diesem mehrzeiligen Text-Feld wird das Zeitintervall eingegeben, in dem der Crawler laufen soll. In der 1. Zeile wird ein CronTab-Ausdruck eingegeben, ab dem der Crawler starten soll. In der 2. Zeile wird ein CronTab-Ausdruck eingegeben, ab dem der Crawler gestoppt werden soll. CronTab-Ausdrücke sind leider nicht stringent standardisiert. Die hier zur Verwendung kommende Muster enthält eine Liste mit 6 durch Leerzeichen getrennte Felder:
Beispiele:
|
||||||||||||||
11 |
IgnoreRobotsMeta-CheckBox |
Die Aktivierung dieser Checkbox bewirkt, dass alle Robots-Meta-Tags und X-Robots-Tag im HTTP-Header ignoriert werden. |
||||||||||||||
12 |
IgnoreRobotsTxt-CheckBox |
Die Aktivierung dieser Checkbox bewirkt, dass die auf Webseiten verlinkte Datei Robots.txt ignoriert wird. |
||||||||||||||
13 |
IgnoreSiteMaps-CheckBox |
Die Aktivierung dieser Checkbox bewirkt, dass Sitemaps ignoriert als nicht indexiert werden. |
||||||||||||||
14 |
IndexedDocumentsCount-NumberField |
Die vom Crawler zu indexierenden Dokumente können gesammelt werden und in Bündeln an den Indexer weitergegeben werden. In diesem Feld wird angegeben wie viel Dokumente parallel an den Indexer übergebenen werden. |
||||||||||||||
15 |
GETRequestWaitingTime-NumberField |
Wartezeit zwischen 2 Requests. Da ein Crawl eine Website durch viele Requests stark belasten kann, kann zwischen 2 Website-Requests eine Wartezeit definiert werden, die in diesem Feld spezifiziert werden kann. Je länger der Wert der Wartezeit, desto länger dauert ein Durchlauf einer Website. |
||||||||||||||
16 |
ThreadCount-NumberField |
Anzahl paralleler Threads |
||||||||||||||
17 |
OrphanedPagesStragegy-Selection-DropDown |
Die Angabe der Strategie mit denen verwaiste Seiten (Seiten die nicht referenziert werden) behandelt werden.
|
||||||||||||||
18 |
ServerErrorPagesStragegy-Selection-DropDown |
Die Angabe der Strategie mit denen Seiten behandelt werden, deren Anfrage gerade komplett fehlgeschlagen ist. Zum Beispiel wenn die Serververbindungen durch Neustart/Crashes unterbrochen sind.
|
||||||||||||||
19 |
ContentTagsIndexing-MultilineEditfield |
In diesem Multiline-TextFeld können Tags oder Zeichenketten angegeben werden, zwischen denen der Inhalt nicht indexiert werden soll.
Auch die Blöcke werden entfernt.
Pro Zeile wird jeweils ein Block-Anfang, drei Punkte und das Block-Ende angegeben.
Statt eines Block-Anfangs kann auch Achtung bei der Verwendung eines HTML-Dokuments mit vielen Beispiel: start-of-file...</nav> <Block-Anfang String...<Block-Ende String> <header...</header> <div class="some-special-class">...end-of-file <!--googleoff: all-->...<!--googleon: all--> |
||||||||||||||
20 |
ResetCrawler-Button |
Löscht den Crawler inkl. aller Status-Informationen |
4.10. Monitoring
4.10.1. Einleitung
Für die Überwachung der CSA stehen folgende Optionen zur Verfügung die über Menüpunkte angesteuert werden können
| Menüpunkt | Monitor | Beschreibung | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Monitor |
Prozess-Monitor |
Der Prozess Monitor bindet eine Applikations-Konsole ein in der alle CSA gehörenden Service-Applikationen aufgelistet werden. Für jeden der Service können die entsprechenden Betriebs-Parameter und Log-Informationen eingelesen und konfiguriert werden. |
||||||||||||||||||||||
Crawler |
Crawler-Monitor |
Der Crawler-Monitor listet alle Crawler-Instanzen auf und stellt den jeweiligen Arbeits-Status der Crawler dar. |
||||||||||||||||||||||
Reports |
Such-Reports |
Mit den Such-Reports werden Statistiken über die Suchaktivitäten auf der CSA dargestellt. Die Rohdaten können in .csv Dateien exportiert werden. |
||||||||||||||||||||||
Index-Infos |
Index-Monitor |
Der Index-Monitor listet die auf der CSA angelegten Indices auf:
|
4.11. Index Backup/Restore-Konfiguration
4.11.1. Einleitung
Die Backup/Restore Funktion dient dazu, eine Konfiguration anzulegen durch welche ein automatisches Backup der angegebenen Indexe durchgeführt wird. Diese können anschließend auch gelöscht - oder auch wieder restored werden.
4.11.2. Aufbau der Konfiguration und Benutzeroberfläche
Backup
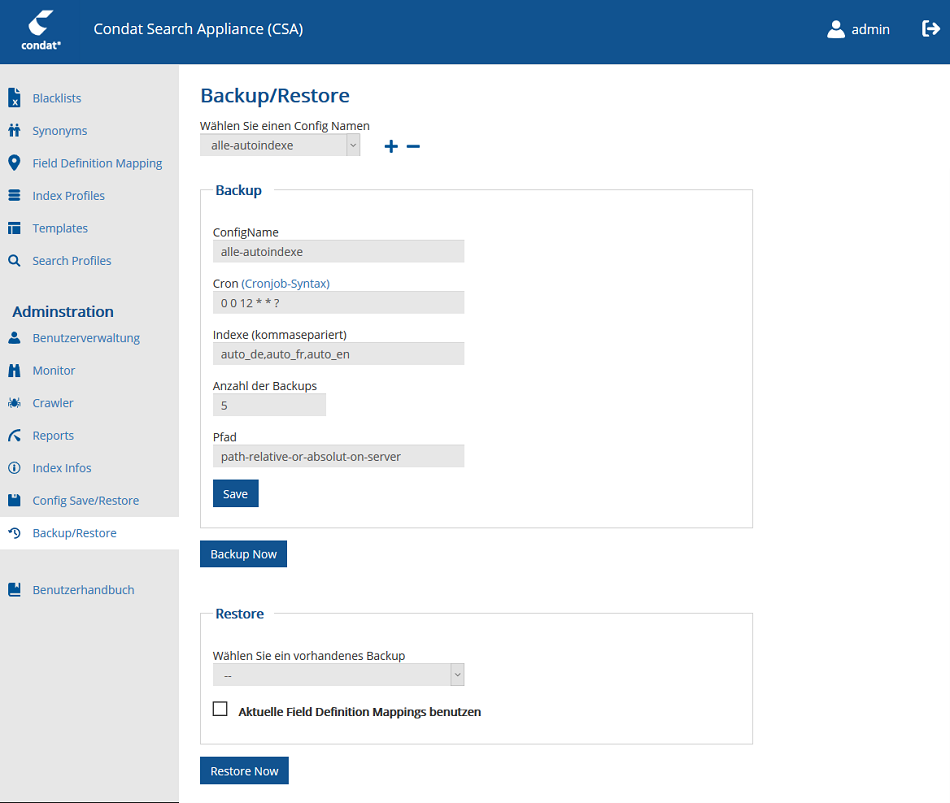
| Feldname (Backup) | Funktion |
|---|---|
ConfigName |
Name der Konfiguration. |
CRON |
Im CRON Feld wird eine Zeit für den Scheduler angelegt. Je nach Angabe wird dann automatisch ein Backup ausgeführt. Cronjob-Syntax |
Indexe (kommasepariert) |
Dieses Feld bestimmt welche Indexe im Backup berücksichtigt werden sollen. Falls es leer gelassen wird, werden alle Indexe im Backup verwendet. |
Anzahl der Backups |
Diese Zahl bestimmt, wie viele Backups maximal gespeichert werden sollen. Wird die Zahl überschritten, werden die ältesten Backup dieser Konfiguration gelöscht. Wird diese Zahl auf 0 gesetzt, können so alle Backups gelöscht werden. |
Pfad |
Der Pfad gibt das Verzeichnis an, in dem die Backup Dateien liegen sollen. |
Mit Save wird die Konfiguration gespeichert. Mit Backup Now wird direkt ein Backup für die Konfiguration ausgelöst. Diese muss allerdings davor schon einmal gespeichert worden sein!
Restore
Im Absatz Restore werden die vorhandenen Backups anhand ihrer Confignamen und Zeitstempel angezeigt. Von den vorhandenen Backups kann eines ausgewählt werden und mit Restore Now wird der aktuelle Stand der Indexe gelöscht und durch das Backup ersetzt.
Zusätzlich gibt es noch die Checkbox Aktuelle Field Definition Mappings benutzen vorhanden. Im Normalfall ist diese nicht ausgewählt und Mappings und Settings des alten Backups werden für den Restore genutzt. Wurden aber Änderungen am Field Definition Mapping vorgenommen, die auch nach dem Backup bestehen bleiben sollen, so müssen die aktuellen Mappings und Settings benutzt werden. Dafür muss in Index-Profiles-Konfiguration der Index neu angelegt werden und dann das Backup mit der ausgewählten Checkbox gestartet werden.
Schritt-für-Schritt Anleitungen
Anlegen einer neuen Backup Konfiguration
-
Klicken Sie auf das Pluszeichen neben dem Drop-Down Feld der Config Namen.
-
Wählen Sie einen geeigneten Config Namen
-
Falls das Backup automatisch ausgeführt werden soll, geben Sie bitte einen CRON-Job an. Dabei ist es wichtig, dass Sie sich an die richtige Syntax halten. Sie können das Feld auch leer lassen, dann muss das Backup allerdings immer manuell ausgeführt werden. Beispiel:
0 0 0 * * ?- täglich mitternachts -
Geben Sie alle Indexe, die Sie verwenden wollen an. Trennen Sie diese bitte per Kommazeichen. Beispiel:
auto_de,auto_fr,auto_en -
Geben Sie die Anzahl der Backups als Zahl an. Beispiel:
5 -
Geben Sie nun den Pfad des Verzeichnisses, in dem die Backups liegen sollen, an.
-
Klicken Sie auf Save.
Löschen einer Backup Konfiguration
-
Wählen Sie die Konfiguration aus.
-
Klicken Sie auf das Minus Zeichen neben dem Drop-Down Feld
-
Bestätigen Sie, dass Sie die Konfiguration wirklich löschen wollen
5. APIs
5.1. Admin API
5.1.1. Allgemein
Die Technischen Schnittstellen dienen der Automatisierung der Konfigurationen.
5.1.2. Anmeldung an der CSA
# Einloggen mit $USERNAME, $PASSWORD und $DOMAINNAME und Cookie herunterladen
curl -X POST -c cookie.txt -F "username=$USERNAME" -F "password=$PASSWORD" http://$DOMAINNAME:8080/login
# weitere Nutzung des Cookies. Beispiel:
curl -X GET -b cookie.txt -H 'Content-Type: application/json' "$DOMAINNAME:8080/")Die Benutzung der Technischen Schnittstellen erfolgt über die Anmeldung an der Administrations-GUI.
Die Anmeldung erfolgt analg des Anmelde-Dialogs über die Eingabe von Username/Passwort.
5.1.3. Field Definition Mapping
Beschreibung
Das ist ein Bereich der Administration, welcher zur Verwaltung der Mappings dient.
Schnittstelle/Endpoint-Bescheibung
Die Anforderung der "Field Definition Mapping" wird in der technischen Dokumentation des Index API beschrieben.
Für das "Field Definition Mapping" wurden die folgenden Methoden implementiert.
| Methode | Aufruf | Parameter | Beschreibung |
|---|---|---|---|
fielddefinition |
/fielddefinition |
|
"Field Definition Mapping"-Bereich öffnen |
deleteFielddefinition |
/fielddefinition/delete |
mapping: Name des zulöschenden Mappings |
Löschen eines Mappings |
editFielddefinition |
/fielddefinition/edit |
mapping: Name des zubearbeitenden Mappings |
Existiert das angegebene Mapping, öffnet sich
eine Seite zur Bearbeitung des Mappings. |
newFielddefinition |
/fielddefinition/new |
|
Öffnet eine Seite zum
Anlegen eines neues Mappings |
saveMapping |
/fielddefinition/save |
vomapping: Daten des neuen oder geänderten Mappings |
Speichern das neu erstellte oder veränderte
Mapping. |
Einrichtung und Bedienung
Der Admin-Service muss gestartet werden.
Der Bereich ist über die URL http://<servername>:8080/admin/fielddefinition zu
erreichen.
5.1.4. Index Profile
Beschreibung
Das ist ein Bereich der Administration, welcher zur Verwaltung der Profile dient.
Schnittstelle/Endpoint-Bescheibung
Für "Profile verwalten" wurden die folgenden vier Methoden in der Klasse MainController.java implementiert.
| Methode |
Aufruf |
Parameter |
Beschreibung |
|---|---|---|---|
profilmanager |
/admin/profilmanager |
|
Öffnet den "Profile"-Bereich |
deleteProfil |
/admin/profilmanager/delete |
profile: Name des zulöschenden Profiles |
Löschen ein Mapping |
editProfile |
/admin/profilmanager/edit |
profile: Name des zubearbeitenden Profiles |
Existiert das angegebene Profil, öffnet sich eine Seite zur
Bearbeitung des Profiles. |
newProfile |
/admin/profilmanager/new |
|
Öffnet eine Seite zum Anlegen neues
Profiles |
Einrichtung und Bedienung
Der Admin-Service muss gestartet werden.
Der Bereich ist über die URL http://<servername>:8080/admin/profilmanager zu
erreichen.
5.1.5. Suchprofile
Beschreibung
Das ist ein Bereich der Administration, welcher zur Verwaltung der Suchprofile dient.
Schnittstelle/Endpoint-Bescheibung
Für "Suchprofil verwalten" wurden die folgenden vier Methoden in der Klasse SearchProfileController.java implementiert.
MVC-Model-Endpunkte
| Methode | Aufruf | Parameter | Beschreibung |
|---|---|---|---|
searchprofilmanager |
/admin/searchprofile |
|
Öffnet den "Searchprofiles"-Bereich |
deleteSearchprofile |
/admin/searchprofile/delete |
profile: Name des zulöschenden Suchprofiles |
Löschen ein Suchprofil. |
editSearchprofile |
/admin/searchprofile/edit |
profile: Name des zubearbeitenden Suchprofiles |
Existiert das angegebene Suchprofil, öffnet sich eine Seite zur Bearbeitung des Suchprofiles. |
newSearchprofile |
/admin/searchprofile/new |
|
Öffnet eine Seite zum Anlegen neues Suchprofiles |
saveSearchprofile |
/admin/searchprofile/save |
vosearchprofile : Daten des neuen oder geänderten Suchprofiles |
Speichern das neu-erstellte oder
veränderte Suchprofil. |
REST-Endpunkte
Es stehen 3 Rest-Endpunkte zur Verfügung. Sie erlauben ein automatisiertes Administrieren der Search-Profile. Die Endpunkte können mit BasicAuth verwendet werden, anstatt sich mit dem Login eine Session zu holen. Die Rolle search_profiles muss vorhanden sein. Die Felder werden im Swagger über den GET-Endpunkt beschrieben. Über den PUT-Endpunkt können auch nur Teile des Profils verändert werden (intern findet ein Merge mit dem existierenden Profile statt). Über den PUT-Endpunkt können auch neue Search Profile anlegen werden.
GET, PUT, DELETE /admin/searchprofile/model/<searchProfile>
Beispiele mit Teilmenge des Bodies für PUT
{
"profileName": "test"
}oder
{
"profileName": "test",
"customPayload": "{\"test\": 1}"
}Einrichtung und Bedienung
Der Admin-Service muss gestartet werden.
Der Bereich ist über die URL http://<servername>:8080/admin/searchprofile zu
erreichen.
| Feld | Value | Mandatory | Beschreibung |
|---|---|---|---|
Default Operator |
and, or (default) |
ja |
Wenn mehrere Suchwörter in einer Suchanfrage eingegeben werden, sollen nur Dokumente angezeigt werden, die: and: Alle Wörter enthalten (Suchraumeingrenzung) or: Mindestens eines der Wörter enthält (Suchraumerweiterung) |
Default MultiMatchType |
BEST_FIELDS (default), MOST_FIELDS, CROSS_FIELDS, PHRASE, PHRASE_PREFIX |
ja |
BEST_FIELDS - durchsucht alle Felder nach den Suchwörtern und gibt den Score des besten Feldes zurück, in Kombination mit "Default Operator"=and, müssen alle Suchwörter in einem Feld enthalten sein! MOST_FIELDS - durchsucht alle Felder und gibt den Score des durchschnittlichen Score der Feldes zurück, in Kombination mit "Default Operator"=and, müssen alle Suchwörter in einem Feld enthalten sein! CROSS_FIELDS - durchsucht alle Felder und gibt den Score des durchschnittlichen Scores zurück. Analysiert die Suchwörter und sucht für jedes Suchwort einzeln. In Kombination mit "Default Operator"=and, müssen alle Suchwörter vorhanden sein, sie dürfen aber in verschiedenen Feldern stehen. PHRASE - durchsucht alle Felder und behandelt die Suchanfrage als eine komplette Phrase, die in genau dieser Reihenfolge komplett in einem Field enthalten sein muss. Der "Default Operator" spielt dadurch keine Rolle. PHRASE_PREFIX - durchsucht alle Felder und behandelt die Suchanfrage als eine komplette Phrase, die in genau dieser Reihenfolge komplett in einem Field enthalten sein muss. Das letzte Wort der Phrase muss nicht vollständig sein, sondern nur ein Prefix des Wortes. Der "Default Operator" spielt dadurch keine Rolle. |
5.1.6. Templates
Beschreibung
Das ist ein Bereich der Administration, welcher zur Verwaltung der Templates dient.
Schnittstelle/Endpoint-Bescheibung
Für "Template verwalten" wurden die folgenden Methoden implementiert.
| Methode |
Aufruf |
Parameter |
Beschreibung |
|---|---|---|---|
templatemanager |
/admin/template |
|
Öffnet den "Template verwalten"-Bereich |
deleteTemplate |
/admin/template/delete |
template: Name des zulöschenden Templates |
Löschen ein Template. |
editTemplate |
/admin/template/edit |
template: Name des zubearbeitenden Templates |
Existiert das angegebene Template, öffnet sich eine Seite
zur Bearbeitung des Templates. |
newTemplate |
/admin/template/new |
|
Öffnet eine Seite zum Anlegen neues
Templates |
saveTemplate |
/admin/template/save |
votemplate: Daten des neuen oder geänderten Templates |
Speichern das neu-erstellte oder veränderte Template. |
Einrichtung und Bedienung
Der Admin-Service muss gestartet werden.
Der Bereich ist über die URL http://<servername>:8080/admin/template zu
erreichen.
Im Folgenden wird beschrieben, was die einzelnen Felder bedeuten und insbesondere wie ein Template mit handlebars gebaut wird.
| Feld |
Beschreibung |
|---|---|
Select-Box "Choose a template to edit" |
Das Feld zeigt die Namen der
vorhanden Templates an |
Name, pflicht |
Name des zu bearbeitenden Templates |
Beschreibung, optional |
Beschreibung des Templates |
Template, pflicht |
Das eigentliche Template.
#each results
<li>
<article>
#if target
<a href="target">target</a>
/if
#if fields
<p>
#each fields
@key: this
/each
</p>
/if
</article>
</li>
/each
|
|
|
Algorithmus / Funktionale Abfolge / Ablaufprozess
Beim Starten des Admin-Services wird der Index "intern_templates" angelegt, wenn dieser noch nicht vorhanden ist. Das Default-Template, welches aus /template/handelbars/index.hbs eingelesen wird, wird mitangelegt.
5.1.7. Blacklists
Beschreibung
Das sind zwei Bereiche der Administration, welche zur Verwaltung der Blacklist bzw. Synonym dienen.
Schnittstelle/Endpoint-Bescheibung
Für Blacklist wurden die folgenden Methoden implementiert.
| Methode | Aufruf | Parameter | Beschreibung |
|---|---|---|---|
blacklist |
/admin/blacklist |
|
Blacklist-Bereich öffnen |
deleteBlacklist |
/admin/blacklist/delete |
language: Analyzer der zulöschenden Blacklist |
Löschen der Blacklist |
editBlacklist |
/admin/blacklist/edit |
language: Analyzer der zubearbeitenden Blacklist |
Existiert die Blacklist mit dem angegebenen Analyzer, öffnet sich eine Seite zur Bearbeitung der Blacklist. |
newBlacklist |
/admin/blacklist/new |
|
Öffnet eine Seite zum Anlegen einer neuen Blacklist |
saveBlacklist |
/admin/blacklist/save |
vowording: Daten der neuen oder geänderten Blacklist |
Speichert die neu erstellte oder veränderte
Blacklist. Blacklist kann manuell eingetragen oder auch durch eine
CVS-Datei importiert werden. |
Einrichtung und Bedienung
Der Admin-Service muss gestartet werden.
Die Blacklists Verwaltung ist über die URL http://<servername>:8080/admin/blacklist zu erreichen.
5.1.8. Synonyms
Beschreibung
Das sind zwei Bereiche der Administration, welche zur Verwaltung der Synonym dienen.
Schnittstelle/Endpoint-Bescheibung
Für Synonym wurden die folgenden Methoden implementiert.
| Methode | Aufruf | Parameter | Beschreibung |
|---|---|---|---|
synonym |
/admin/synonym |
|
Synonym-Bereich öffnen |
deleteSynonym |
/admin/synonym/delete |
language: Analyzer des zulöschenden Synonyms |
Löschen des Synonyms |
editSynonym |
/admin/synonym/edit |
language: Analyzer des zubearbeitenden Synonyms |
Existiert das Synonym mit dem angegebenen Analyzer, öffnet sich eine Seite zur Bearbeitung des Synonyms . |
newSynonym |
/admin/synonym/new |
|
Öffnet eine Seite zum Anlegen einer neuen Synonymliste |
saveSynonym |
/admin/synonym/save |
vowording: Daten des neuen oder geänderten Synonyms |
Speichert das neu erstellte oder veränderte
Synonym. Synonym kann manuell eingetragen werden oder auch durch eine
CVS-Datei importiert werden. |
Einrichtung und Bedienung
Der Admin-Service muss gestartet werden.
Die Synonym Verwaltung ist über die URL http://<servername>:8080/admin/synonym zu erreichen.
6. Index API
Die Indexierung von Dokumenten wird vom Index-Service bereitgestellt und kann über eine REST-Schnittstelle aufgerufen werden.
Die Indexierung von Dokumenten wird vom Index-Service bereitgestellt und kann über eine REST-Schnittstelle aufgerufen werden.
Der Indexierungsprozess erfolgt sequenziell:
-
zunächst wird ein CSA Dokument an den Index-Service geschickt
-
Das Dokument wird zunächst validiert. Das bedeutet, dass das Format und Pflichtfelder geprüft werden. Zusätzlich werden die
fields-Werte gegen das Mapping, dass im Profil referenziert wird, geprüft. -
wenn das Feld
target_documentim CSA Dokument vorhanden ist, holt der Index-Service den Inhalt der URL und analysiert diesen mit Hilfe von Tika-
Je nach Konfiguration werden durch diese Analyse weitere
fieldsautomatisch angelegt
-
-
Ist alles fehlerfrei, wird das CSA Dokument gespeichert und steht für die Suche zur Verfügung
-
Alle fields-Werte mit einem Analyzer normalisieren Sonderzeichen/Akzente sowohl bei der Indexierung, als auch bei der Suche. Rechtsschreibfehler bei Sonderzeichen führen also trotzdem zu Treffern.
-
Alle fields-Werte mit einem Analyzer entfernen HTML-Tags und einige HTML-Hyphen (konfigurierbar)
-
-
Die ID die beim Anlegen erzeugt wird ist ein hashwert der URL aus dem Feld target.
6.1. Endpoints
Der Index-Controller kann Dokumente anlegen und löschen.
| Pfad | Methode | Parameter | Funktion | Fehler | Response |
|---|---|---|---|---|---|
|
POST |
|
Indexiert eine Menge von Dokumenten |
200
Dokumente wurden upgedatet |
leer oder Fehler-JSON |
|
DELETE |
|
Löscht ein einzelnes Dokument |
200 Dokument wurde gelöscht |
leer oder Fehler-JSON |
6.1.1. Dokumentfeed
Ein Dokumentfeed ist eine Liste von CSA Dokumenten und hat eine Menge von Default-Feldern.
Default-Felder
Folgende Felder (mit entsprechenden Datentypen) sind per Default an jedem ES-Dokument vorhanden:
-
id(intern): Identifier (String) -
filetype: Typ des Dokuments (HTML, PDF, DOC, XLS, alles, was Apache Tika verarbeitet) -
modified: Datum. an dem das Dokument zuletzt geändert wurde -
indexed(intern): Datum. an dem das Dokument indexiert wurde -
version(intern): Interne Version des Dokuments -
target: URL (auch relativ) zum auszuspielenden Dokument
Die als intern gekennzeichneten Felder dürfen nicht im zu indexierenden Dokument gesetzt sein, sie werden bei der Indexierung gesetzt.
Beispiel:
[
{
"id": "124810392486",
"filetype": "html",
"modified": "2017-06-01T11:34:50+00:00",
"target": "https://csa.condat.de/",
"fields": {
"title": "Eine Beispielseite",
"content": "Beispielcontent mit viel Text"
}
},
{
"id": "124810392487",
"filetype": "pdf",
"modified": "2017-06-01T11:34:50+00:00",
"target": "https://csa.condat.de/download/csa.pdf",
"target_document": "https://csa.condat.de/download/csa.pdf",
"fields": {
"title": "Basisdaten der CSA"
}
}
]Ein CSA Dokument kann zwei Ausprägungen haben:
- Metadaten
-
Es gibt eine Menge von Feldern unterhalb von
fields. Genau diese werden für die Suche indexiert. - Feeding-Dokument
-
Ein Feeding-Dokument besitzt zusätzlich eine URL, deren Inhalt indexiert werden soll. Der IndexService holt sich dann den Inhalt und transformiert/analysiert diesen. Dafür gibt es das Feld:
-
target_document: URL (auch relativ) zum Dokument, das geholt und indexiert werden soll
-
Das Feld target wird nur für die Rückgabe im Suchergebnis benutzt.
Das Feld target_document kann die gleiche URL sein.
Es kann aber auch eine angepasstere URL sein.
Zum Beispiel gibt es in Content Management Systemen oft die Möglichkeit, statt dem ganzen Inhalt incl. Header und Footer, nur den echten Content zurückzuliefern.
Weitere Felder können als Metadaten unterhalb von fields angegeben werden und überschreiben dann ggf. im Dokument gefundene.
In einem zu indexierenden Dokumententfeed können reine Feeding-Dokumente und Metadaten Dokumente bunt durcheinandergewürfelt werden.
Beispiel (nur Metadaten):
{
"id": "124810392486",
"filetype": "html",
"modified": "2017-06-01T11:34:50+00:00",
"target": "https://csa.condat.de/",
"fields": {
"title": "Eine Beispielseite",
"content": "Beispielcontent mit viel Text"
}
}Beispiel Feeding-Dokument (mit Metadaten)
{
"id": "124810392486",
"filetype": "html",
"modified": "2017-06-01T11:34:50+00:00",
"target": "https://csa.condat.de/download/csa.pdf",
"target_document": "https://csa.condat.de/download/csa.pdf",
"fields": {
"title": "Eine Beispielseite"
}
}Beispiel Feeding-Dokument (ohne Metadaten)
{
"id": "124810392486",
"filetype": "html",
"modified": "2017-06-01T11:34:50+00:00",
"target": "https://csa.condat.de/download/csa.pdf",
"target_document": "https://csa.condat.de/download/csa.pdf",
}6.1.2. Beispiel Dokument anlegen:
curl -X POST --header 'Content-Type: application/json' --header 'Accept: application/json' -d '[ \
{ \
"fields": { \
"titel": "Hallo Welt", \
"text": "....." \
}, \
"filetype": "html", \
"modified": "2017-07-19T09:50:14.488Z", \
"target": "http://server/test.html", \
"target_document": "http://server/test.html" \
} \
]' 'http://localhost:8081/index/<profilname>'6.1.3. Beispiel Dokument löschen:
curl -X DELETE --header 'Accept: application/json' 'http://localhost:8081/index/<profilname>?docId=<id oder url>'6.2. Management Endpoints
Der Index-Manager-Controller kann Indizes über einen Profilnamen anlegen und löschen.
| Pfad | Methode | Parameter | Funktion | Fehler |
|---|---|---|---|---|
|
PUT |
|
Erzeugt einen Index |
201 Index erzeugt |
|
DELETE |
|
Löscht einen Index |
200 Index geklöscht |
6.2.1. Beispiel Index anlegen
curl -X POST --header 'Content-Type: application/json' --header 'Accept: application/json' 'http://localhost:8081/index/create/<profilname>'*6.2.2. Beispiel Index löschen
curl -X POST --header 'Content-Type: application/json' --header 'Accept: application/json' 'http://localhost:8081/index/delete/<profilname>'*7. Search API
Die Volltextsuche ist eine Suche, die mittels Suchbegriffen in den im ElasticSearch indexierten Dokumenten sucht und alle Dokumente zurückliefert, die mindestens einen Treffer unter den Suchbegriffen hatten. Die Suche befindet sich im Search-Service und kann mit einem RestController als GET-Request aufgerufen werden.
Nachdem ein GET-Request an den search-endpoint geschickt wurde, werden
alle Parameter validiert und ggf eine entsprechende Fehlermeldung mit
HTTP-Statuscode 400 zurückgegeben.
Findet die Validierung keine Fehler, so wird eine ElasticSearch-Query
aus den Suchparametern aufgebaut und an das konfigurierte ElasticSearch
geschickt.
-
ElasticSearch führt die in den Search-Parametern definierten Filter aus. Das führt zu einer Reduzierung der Anzahl der Dokumente, für die die Volltextsuche ausgeführt werden soll und damit zu einer Beschleunigung der Suche.
-
Für die Volltextsuche werden alle Felder durchsucht, die im Mapping (siehe [Basis-Konfiguration]) vom Typ=text sind und im SearchProfil die Checkbox Volltextsuche ausgewählt haben. Alle diese Felder und die Suchanfrage selbst werden dabei durch einen ElasticSearch-Analyzer (zum Beispiel 'german') auf dieselbe Form gebracht. Es reicht eines der Suchwörter (bzw beim Analyzer 'german' den passenden deutschen Wortstamm) zu finden. Werden in einem Dokument mehrere Treffer erziehlt, steigt der ElasticSearch-Score und das Dokument rückt in der Trefferliste weiter nach vorn.
-
Am Ende arbeitet ElasticSearch die Suchergebnisse je nach vorgegebenen Sortierungen, From und Size auf.
-
Der Search-Service konvertiert die ElasticSearch-Suchergebnisse in das spezifizierte SearchResults-Format. Er fügt die in
fieldangegebenen Felder in jeden SearchResult hinzu und erweitert ggf. die Antwort um Highlighting und Suggestions (Did-You-Mean).
7.1. Endpoints
| Pfad | Methode | Response | Parameter | Funktion | Fehler |
|---|---|---|---|---|---|
|
GET und POST (für längere Suchanfragen) |
JSON |
Parameter siehe unten |
Sucht Dokumente |
400
Falsche Parameter/Parameterformate, Profil nicht gefunden |
|
GET und POST (für langere Suchanfragen) |
HTML |
Parameter siehe unten |
Sucht Dokumente |
400
Falsche Parameter/Parameterformate, Profil nicht gefunden |
|
GET |
JSON |
Parameter siehe unten |
Gibt Vorschläge, wie ein zu tippen begonnenes Suchwort vervollständigt werden könnte |
400
Falsche Parameter/Parameterformate, Profil nicht gefunden |
7.1.1. Search-Parameter
-
q:String- Query, siehe: Volltextsuche -
pr|profile:String- Name des Suchprofils, steuert die Ausgabe (optional) siehe: [Profile] -
fi|filter:Filter- Filter (optional) siehe: Filter -
pfi|postfilter:Filter- Postfilter (optional) siehe: Postfilter -
so|sort:String- Sortierung (optional), siehe: Volltextsuche -
ex|explain:Boolean- Sucherklärung ausgeben (optional), siehe: Volltextsuche -
fr|from:Integer- Offset der Ergebnisse (optional), siehe: Volltextsuche -
si|size:Integer- maximale Anzahl Ergebnisse (optional), siehe: Volltextsuche -
fd|field:String- Felder, die im Ergebnis mit ausgegeben werden sollen (optional, mehrfach), siehe: Volltextsuche -
hd|hide:String- Felder, die im Ergebnis nicht ausgegeben werden sollen (optional, mehrfach), aber für die Suche, das Boosting oder das Scoring benötigt werden. -
bo|boost:String- Boost von Felder zur Anfragezeit (optional, mehrfach) siehe [Boosts] -
fs|fulltextsearch- Felder, die bei der Volltextsuche benutzt werden sollen (so können Felder explizit von der Volltextsuche ausgenommen werden), siehe Volltextsuche -
ps|prefixsearch- Felder, die auch für eine Prefixsuche benutzt werden sollen, siehe Prefixsuche -
fa|facet:String- Liste von Feldnamen, die facettiert werden sollen und ihrer maximalen Anzahl an zurückgegebenen Facetten siehe Facets -
hi|highlight:Boolean- Highlighting ausgeben (optional), siehe: [Highlighting] -
su|suggestion:Boolean- DidYouMean/Suggestions ausgeben (optional), siehe: [DidYouMean] -
te|template:String- Template (optional, nur HTML) siehe: Templates -
sc|score:String- Nachträgliche Veränderung des Scores siehe: Einleitung -
sep|searchEndpoint- Bei self, first, next, prev kann der Endpunkt überschrieben werden, zu einer beliebigen URL, es muss die komplette URL sein, nur ohne Parameter, also zum Beispiel: http://hostname:8080/search/searchJson
7.1.2. Typeahead-Parameter
-
q:String- Query -
spr|searchprofile:String- Name des Suchprofils (optional, ohne Angabe wirdspr=defaultgesetzt) -
ty|typeahead:String- Felder, deren Wörter das Typeahead bilden (optional, mehrfach), siehe: [Typeahead] -
fi|filter:Filter- Filter (optional) siehe: Filter -
pfi|postfilter:Filter- Postfilter (optional) siehe: Postfilter -
si|size:Integer- maximale Anzahl an Typeahead Worten (optional), siehe: [Typeahead] -
bo|boost:String- Boost von Felder zur Anfragezeit (optional, mehrfach) siehe [Boosts]
Die oberen Parameter werden auf folgender Seite beschrieben: [Typeahead]
7.1.3. Suchprofil
Ein Suchprofil steuert zum einen die Suche, indem es z.B. Teile des Queries wie Filter vorgibt, zum anderen legt es fest, mit welchem Template die Ausgabe gerendert wird.
7.1.4. Template
Ein Template steuert das HTML-Rendering.
7.1.5. Facetten
Der API-Nutzer kann eine parametrisierte Suchanfrage absetzen mit der im Suchergebnis eine Struktur zurückgegeben wird, die Such-Facetten enthält. Damit kann das Suchergebnis gezielt über Facettenwerte gefiltert werden.
Mit dem facet|fa Parameter lassen sich gezielt einzelne Facetten einschalten. Mehrere Facetten sind nach ihrem Key alphabetisch sortiert. Innerhalb einer Facette wird nach der Anzahl der Dokumente sortiert.
-
Validierung:
-
jeder Feldname darf nur einmal benutzt werden (nur eine facetSize und minDocSize haben)
-
es dürfen nur Feldnamen benutzt werden, die vom Mapping-Type=keyword sind
-
Feldname, facetSize und minDocCount sind mit einem Doppelpunkt voneinander getrennt
-
die facetSize muss eine ganze positive Zahl größer 0 sein oder leer
-
der minDocCount muss eine ganze positive Zahl größer gleich 0 sein oder leer
-
facet=feldname, facet=feldname:, facet=feldname:: sind äquivalent und bezeichnen eine Facette mit Defaultwerten für facetSize und minDocCount.
Parameter-Key Value Default Mandatory Beschreibung facet|fa
facet=feldname[:facetSize[:minDocCount]]
facetSize = search.yml ⇒ search.defaultFacetSize
-
Für alle in facet aufgelisteten Feldern werden Facetten generiert. Die facetSize ist optional und bezeichnet die maximal anzuzeigenden Facettenwerte je Facette. Wenn facetSize nicht angegeben ist, dann wird auf den Defaultwert in der search.yml zurückgegriffen.
Zusätzlich kann der optionale Parameter minDocCount angegeben werden. Wenn dieser Wert gesetzt ist, werden nur Facetten zurückgegeben, wenn sie mehr als minDocCount Treffer zurückliefern. Der Defaultwert ist 1. Bei minDocCount=0, werden auch leere Facetten zurückgegeben. Das macht bei klar definierten Facettvalues (genau 10 Farben) Sinn. Bei großen Facettbereichen (Schauspieler oder Jahreszahl) kann es bei minDocCount=0 zu Performanceeinbußen kommen. Und es können Facetten angezeigt werden, die zwar im Index existieren, aber nicht über die Einschränkungen des Suchprofiles gefunden werden können.
-
7.1.6. Filter
Filter definieren harte Kriterien, die für den Erfolg einer Suche erfüllt werden müssen, im Gegensatz zur Query, bei dem nur mindestens ein Suchbegriff gefunden werden muss. Für ein Feld können mehrere Filterkriterien definiert werden, der Filterparameter taucht dann entsprechend mehrfach auf. Die verschiedenen Type=text, keyword, date, num_long, num_double, bool unterscheiden sich in ihrer Filtermöglichkeit.
Beispiel UND-Filter: mehrere filter
-
codiert:
&filter=meta_make%3A%2Ftaxonomy%2Fmake%2Fvw&filter=meta_make%3A%2Ftaxonomy%2Fmake%2Fvwnf -
decodiert:
&filter=meta_make:/taxonomy/make/vw&filter=meta_make:/taxonomy/make/vwnf -
entspricht zwei Filter im Suchprofile:
meta_make:/taxonomy/make/vwundmeta_make:/taxonomy/make/vwnf
Beispiel ODER-Filter: Verwendung des Pipe-Zeichens |
-
codiert:
&filter=standort%3AGlobal%7CBuchs%20ZH%7CMeta -
decodiert:
&filter=standort:Global|Buchs ZH|Meta -
entspricht einem Filter im Suchprofile:
standort:Global|Buchs ZH|Meta
Beispiel NOT-Filter: Verwendung des Ausrufezeichens ! an erster Stelle eines Filters
-
codiert:
&filter=!standort%3AGlobal%7CBuchs%20ZH%7CMetaoder&filter=!path:/a/b/c -
decodiert:
&filter=!standort:Global|Buchs ZH|Meta -
entspricht einem Filter im Suchprofile:
!standort:Global|Buchs ZH|Meta -
bei der Kombination mit ODER-Filter, wird der komplette ODER-Filter verneint. Das entspricht etwa: NOT (a OR b OR c)
Es gibt folgende Filter:
| Syntax Filter-Parameter | Beschreibung |
|---|---|
|
Ergebnisse, in denen Feld |
|
Ergebnisse, in denen Feld |
|
Ergebnisse, in denen Feld |
|
Ergebnisse, in denen Feld |
|
Ergebnisse, in denen Feld |
7.1.7. Postfilter
Postfilter können im Zusammenspiel mit Facetten benutzt werden. Ein Postfilter wird erst nach der Berechnung der Facettenwerte ausgeführt. Damit können ODER-Facetten realisiert werden.
Beispiel: Es gibt Dokumente die jeweils genau einen der Farbwerte farbe=blau, rot oder grün besitzen.
Wird eine * Suche durchgeführt und farbe als Facette gewählt, dann werden alle Dokumente gefunden und die Farb-Facette enthält alle drei Werte.
Nun wählt man eine der Farben aus. Eine neue Suche wird mit dem Filter fi=farbe:blau gestartet, daraufhin sind alle anderen Farb-Facetten verschwunden oder 0.
Möchte man nun auf der Website eine ODER-Facettierung haben, dann benutzt man statt einem filter|fi, den postfilter|pfi, also pfi=farbe:blau.
Daraufhin wird genau das gleihe Suchergebnis zurückgeliefert, aber die Farb-Facetten für rot und grün sind nicht 0, sondern entsprechen der Anzahl der Dokumente, die hinzukämen, würde auch auf eine zweite Farbe geklickt werden.
Das Frontend, bzw der Aufrufende der Suche, muss also entscheiden, ob es sich um einen UND-Facettierung handeln soll und filter|fi nutzen oder bei einer ODER-Facettierung postfilter|pfi nutzen.
Ansonsten hat der postfilter|pfi genau die gleiche Synatax wie der filter|fi.
7.1.8. Boost
Mit dem Parameter bo|boost lassen sich Felder zur Anfragezeit boosten.
Der Wert des Parameters wird als kommaseparierte Liste field:boost
angegeben, wobei jedes Feld nur einmal auftauchen darf und boost als
Fließkommazahl (1.23) geschrieben werden muss. Boosts zur Anfragzeit
überschreiben Boosts, die in Suchprofilen definiert wurden.
7.1.9. Sortierung
Die Sortierung ist per default absteigend nach ES-Score. Es kann jedoch
auch ein oder mehrere Felder angegeben werden, welches eine Zahl, ein Datum oder ein
Keyword enthält, zusammen mit einer erforderlichen Suchrichtung (asc/desc) und kommasepariert.
Im Ganzen: sort=feld:asc|desc,feld2:asc|desc,….
Am Ende wird wird immer automatisch der Score als letztes Sortierkriterium hinzugefügt.
7.1.10. Volltextsuche
Allgemein
Die Hauptaufgabe einer Volltextsuche besteht im Suchen und Finden von Daten/Dokumenten, die eine bestimmte Zeichenkette (Suchstring) enthalten. Je einfacher und präziser sich Anfragen stellen lassen, desto leichter lässt sie sich lösen. Die einfachste Anfrage, die sich an CSA stellen lässt, ist die nach einem konkreten Term, der in der festgelegten Schreibweise in einem Feld vorhanden sein muss.
Platzhalter (Wildcard)-Suche
Platzhalter (Wildcards) sind Symbole, die Zeichen in Suchbegriffen ersetzen um mehr Treffer zu erhalten:
-
* ersetzt kein oder beliebig viele Zeichen.
-
? ersetzt ein Zeichen.
-
Ein Sternchen (*) am Ende eines Wortes bzw. Wortstammes findet diesen Suchbegriff mit unterschiedlichen Wortendungen.
Beispiel: ethi*
Findet Datensätze, die "Ethik", "ethisch", "ethische" etc. enthalten.
-
Ein Sternchen (*) kann auch in der Mitte eines Suchbegriffs stehen und kein oder beliebig viele Zeichen ersetzen.
Beispiel: stammzell*forschung
Findet Datensätze, die "Stammzellforschung" oder "Stammzellenforschung" enthalten. -
Ein Fragezeichen (?) ersetzt ein Zeichen an beliebiger Stelle in einem Suchbegriff.
Beispiel: f?tus
Findet Datensätze, die "Fetus" oder "Fötus" enthalten.
Geschlossene Phrasensuche
Mithilfe von Anführungszeichen lässt sich nach einer bestimmten Wortfolge suchen, die exakt in dieser Reihenfolge vorkommt.
-
Beispiel: "Die schönsten Badestrände Europas"
Findet alle Dokumente in der diese Wortreihenfolge exakt vorkommt.
Bestimmte Worte ausschließen
Möchte man bestimmte Wörter ausschließen, so kann man dies mit einem vorangestellten Minuszeichen machen.
-
Beispiel: smartphone zubehör -iphone
Findet alle Dokumente in denen die Worte smartphone und/oder zubehör vorkommt, schließt jedoch die Dokumente aus, die das Wort "iphone" enthalten.
Prefixsuche
Möchte man, für bestimmte Inhalte, auch Dokumente finden, wenn nur die ersten Buchstaben eines Wortes eingegeben wurden, kann für ein Feld die Prefixsuche aktiviert werden.
Die Prefixsuche sollte nicht auf allen Texten verwendet werden, da die Suchergebnismenge damit stark erhöht wird. Es gibt auch die Möglichkeit der Typeahead-Suche, die direkt im Suchfeld während der Eingabe eines Suchworts, komplette Suchwörter vorschlägt. Damit wird die Suchergebnismenge präzisiert, statt erweitert. Die Typeahead-Suche kann eine gute und effiziente Alternative zur Prefixsuche sein.
Die Prefixsuche kann sehr gut eingesetzt werden, wenn Eigennamen gesucht werden sollen.
-
Beispiel: schach
Findet neben Schach auch Schachspiel, Schachfigur und Schacht
7.1.11. Suchergebnisse (CSA-JSON)
SearchResults
| Datentyp | Beschreibung |
|---|---|
results |
List<SearchResult> |
suggestions |
List<Suggestion> |
first |
URL |
prev |
URL |
next |
URL |
self |
URL |
totalResultsCount |
Long |
facets |
Facets |
SearchResult
| Attribut | Datentyp | Beschreibung | Frage |
|---|---|---|---|
id |
String |
ID des gefundenen Dokuments |
|
score |
Float |
Score des Dokuments |
|
target |
String |
Zieldokument |
(relative) URL des Zieldokuments |
fields |
Map<String, String> |
Felder, die sortiert mit ausgegeben werden (optional) |
|
highlighted |
Map<String, String> |
Feldausschnitte, die mit hervorgehobenen Suchwörtern ausgegeben werden (optional) |
|
Felder
Paare der Form fieldname,value.
Suggestion
| Attribut | Datentyp | Beschreibung |
|---|---|---|
text |
String |
Text der vorgeschlagenen Phrase |
highlighted |
String |
Die vorgeschlagene Phrase mit Hervorhebung der korrigierten Begriffe |
score |
Float |
Score-Wert für die vorgeschlagene Phrase |
Facets
Paare der Form:
| Attribut | Datentyp | Beschreibung |
|---|---|---|
<fieldname> |
List<KeyCountBucket> |
Facetten für ein Feld |
| Attribut | Datentyp | Beschreibung |
|---|---|---|
key |
String |
Attribut-Wert |
docCount |
Integer |
Anzahl der gefundenen Dokumente mit diesem Attribut-Wert (=key) |
7.1.12. Typeahead-Ergebnisse (CSA-JSON)
Typeahead-Ergebnisse
| Datentyp | Beschreibung |
|---|---|
suggestions |
List<TypeaheadResult> |
TypeaheadResult
| Attribut | Datentyp | Beschreibung | Frage |
|---|---|---|---|
text |
String |
Vorschlagwort oder -wörter |
|
score |
Float |
Score-Wert dieses Vorschlags |
|
8. Crawler API
Der CrawlerService durchsucht und analysiert automatisch Webseiten und reicht dem IndexService alle zu indexierenden Webseiten weiter.
Der Crawlerprozess erfolgt vereinfacht in folgenden Schritten:
-
Alle Start-Urls werden der Crawler-Queue übergeben
-
Der Crawler nimmt sich immer wieder eine Url aus der Queue, bis keine mehr vorhanden ist und läd die Webseite dieser Url.
-
Dann werden darin alle Links gesucht und ebenfalls in die Queue gespeichert, falls diese Links erlaubte Links sind.
-
Der Inhalt der Webseite wird mit Hilfe von Analysetools analysiert, ggf wird diese URL auch verworfen, und ansonsten für die Indexierung aufbereitet. (Entfernen von HTML-Tags, Lesen von Metadaten, Generieren von Metadaten, …)
-
Am Ende des Prozesses schickt der Crawler die aufbereiteten Dokumente gebündelt an den Index-Service, der die eigentliche Indexierung übernimmt.
-
-
Hat der Crawler die komplette Webseite mit all ihren Links einmal bearbeitet (die Queue ist leer), dann fängt er wieder von vorne an mit den Start-URLs.
8.1. Endpoints
| Pfad | Methode | Parameter | Funktion | Fehler | Response |
|---|---|---|---|---|---|
|
GET |
|
Gibt ein Dokument zurück, das in diesem Format dem Index-Service übergeben werden kann. Die Schnittstelle wird auch vom Index-Service selbst benutzt, um Dokumente zu analysieren. |
200 Dokumente wurde analysiert |
leer oder Fehler-JSON |
8.2. Management Endpoints
die hier beschriebenen Endpoints müssen noch in den Management Controller wandern
| Pfad | Methode | Parameter | Funktion | Fehler |
|---|---|---|---|---|
|
POST |
|
Startet den im Index Profile definierten Crawler |
200 Crawler gestartet |
|
POST |
|
Stoppt den im Index Profile definierten Crawler |
200 Crawler gestoppt |
|
GET |
|
Gibt den profileName zurück, wenn der Crawler bereits existiert oder existiert hat und noch Daten vorhanden sind (Historie des Crawlers). Gibt null zurück, wenn keine Daten vom Crawler gefunden wurden. |
200 Crawler existiert(e)/nicht |
|
POST |
|
Stoppt und löscht einen Crawler mit all seiner Historie. |
200
Crawler gestoppt |
|
POST |
|
Läd eine neue Konfiguration für den im Index Profile definierten Crawler. Dafür werden folgende Teilschritte ausgeführt:
|
200 Der Crawler läuft mit neuer Konfiguration |
|
POST |
Läd die Konfiguration für den definierten Crawler aus allen Index Profilen. Dafür werden folgende Teilschritte ausgeführt:
|
201 Index erzeugt |
|
|
GET |
Zeigt alle Crawler an, die im CrawlerService derzeit crawlen |
200 Liste der Crawler |
|
|
GET |
Zeigt die komplette Crawler-Queue dieses IndexProfiles an.
|
200 Json Objekt mit den Parametern active, queued, cached, processedInvalid und processedValid, die jeweils eine Liste von Urls enthalten. |
|
|
GET |
Zeigt den Status des Crawlers. Es sind die gleichen Angaben, die man im Crawler Monitor für jeden Crawler sehen kann. |
200 Json Objekt mit duration, note, progress, job, startedOn und status |
|
|
GET |
Zeigt für eine URL, die am besten aus |
200 Json Objekt |
9. CHANGELOG
# 3.1.0 * CSADEV-388 Tests und Anpassung für die Default CrawlerConfig XML, so das sie ohne Feher läd * CSADEV-387 Spring Clound Gateway Bugfix für Query-Parameter-Encoding und Test-UI statisches Callback-Parameter entfernt * CSA Version auf der Adminoberfläche anzeigen * CSADEV-374 Die Endpoints GET, PUT, DELETE /admin/searchprofile/model/<searchProfile> lassen ein automatisiertes Konfigurieren der Searchprofile zu. * CSADEV-370 Im Search-Profile kann in einem customPayload Feld benutzerspezifisches JSON hinterlegt werden. Dieses JSON wird dann in jeder Search-Response zurückgegeben. * CSADEV-376 Mehrere Sortierungen in der Suche zulassen * CSADEV-371 Reihenfolge von Aufzählungen in der UI und von Feldern und Facetten im Search Result nach dem Alphabet (ignore case) sortiert * CSADEV-377 Bei leerer q= werden alle Dokumente zurückgegeben # 3.0.0 * CSADEV-380 Update der CSA auf Elasticsearch 8.15.5 * CSADEV-380 Update der CSA auf Java 21 und Spring Boot 3.4 # 2.15.3 * CSADEV-352 Default Felder trotz Hide ausgeben # 2.15.2 * CSADEV-352 Hide/Verstecken Feld wird nicht mehr bei Highlights verwendet, zusätzlich werden nur noch die technischen Highlight Elasticsearch-Fields genutzt, die in auch in der Query genutzt wurden. # 2.15.1 * CSADEV-352 Hide/Verstecken Feld bis in die Elasticsearch-Query weitergeleitet, so das die Ergebnismenge bereits dort geringer wird. # 2.15.0 * CSADEV-367 Health Endpoint Status aller Java Services in ihre Prometheus Endpoints aufgenommen * CSADEV-359 missing Score im field_value_factor hinzugefügt # 2.14.1 * CSADEV-358 und CSADEV-357 auch bei der Phrasensuche und Wildcardsuche werden die char_filter und das asciifolding angewandt # 2.14.0 * CSADEV-357 Sonderzeichen/Akzente werden sowohl bei der Indexierung, als auch bei der Suche normalisiert. Rechtsschreibfehler bei Sonderzeichen führen also trotzdem zu Treffern. * CSADEV-358 Alle Analyzer vom Type text, unabhängig von Name=META werden verwenden char_filter=["additional_char_filter", "html_strip"]. Die additional_char_filter können in der application.yml konfiguriert werden. Zur Zeit werden ­ hyphen dadurch entfernt. # 2.13.0 * CSADEV-354 In den Filtern wurden die ODER-Filter erweitert. Der EXISTS Filter kann mehrere Feldnamen mit dem | (Oder-)Zeichen verknüpfen. Bei allen anderen Filtern können mehrere Werte mit dem | (Oder-)Zeichen verknüpft werden. Bei keywords ist auch eine Kombination aus PREFXI und HAS_VALUE möglich. Bei long, double und date ist auch eine Kombination aus FROM_TO und HAS_VALUE möglich. # 2.12.0 * CSADEV-352 Hide/Verstecken Feld im SearchController hinzugefügt, jetzt können Felder zwar für die Suche relevant sein, aber trotzdem aus der Ergebnismenge ausgeschlossen werden. * CSADEV-351 CSA Admin - Ein fehlgeschlagener Login führt nun zu einem 401 Unauthorized und nicht mehr zu einem 302 Redirect auf eine Login-Fehlerseite # 2.11.0 * Cralwer: Seiten, die vom Crawler als Rejected markiert wurden, aber einen Statuscode von 200 hatten, bekommen jetzt Fehlermeldungen mit einem Status Code im Bereich von 4xx und werden dadurch verworfen. * CSADEV-349 - CSA im Docker komplett auf den User apprunner umgestellt und process-Volume mit Crawler und Jefmonitor verbunden * CSADEV-348 - CSA Facet Bug in der Admin UI * CSADEV-334 - Warnungen/Hinweise in der Admin UI hinzugefügt # 2.10.1 * Vorläufiger Fix für CVE-2021-44228 für die Elasticsearch Instanz # 2.10.0 * Index-Service: Die Did-You-Mean Indexierung benutzt einen lowercase-Tokenfilter und ist somit jetzt case-insensitiv * KBB-229 Im Field Definition Mapping gibt es einen neuen Datentyp "not_searchable". Dieser definiert ein Feld, dass von der CSA komplett ignoriert wird, nicht für Suche, Filterung oder Scoring zur Verfügung steht. Wenn es im SearchProfile aufgelistet wird, wird es ausgegeben. Der Wert eines solchen Feldes kann ein Einzelwert oder ein Array sein vom Typ Text, Zahl, Boolean, aber auch ein komplettes komplexes JSON Object oder JSON Array. * KBB-223 Es werden auch Facetten-Werte angezeigt, die bei dem aktuellen Suchergebnis gerade nicht vorhanden sind, aber im Index existieren * man kann über das SearchProfile, neben der Anzahl der Facetten, auch den minDocCount=0 pro Facette einstellen können, damit können auch leere Facetten zurückgegeben werden. Was die Benutzung sehr Übersichtlich macht. * es gibt einen neuen Filter pfi, er funktioniert exakt wie der alte Filter, aber dieser Filter läuft erst nach der Facetten-Aggregation ab, deswegen ist sein Name auch pfi|postfilter. Damit können bei einer Oder-Facettierung die alten Facetteneinträge erhalten bleiben. Bei den jetzigen Filter "filter" werden alle anderen Aggregationszahlen zu 0, wenn ein Keyword gefiltert wurde. # 2.8.0 * Der Admin triggert seinen eigenen Refresh jetzt über ein POST-Request, damit im Clusterbetrieb dieser Request auf alle verhandenen Admins verteilt werden kann. * Der Crawler ist clusterfähig, wenn er mit dem Property csaDatastore: elasticsearch gestartet wird. Dann werden alle Crawldaten ins Elasticsearch gespeichert und jeder aktive Crawler bedient sich aus dem Elasticsearch. * Integrationstests für den Crawler erweitert. # 2.7.2 * Http Anfragen mit einem Accept-Header Stream über den Zuul Proxy werden gestoppt und 200 OK zurückgegeben, da der Zuul Proxy nicht mit Streams umgehen kann. # 2.7.1 * Die Crawler haben eine eigene HttpClient RedirectStrategy bekommen, sie versucht Redirect URLs auch dann zu lesen, wenn die URLs nicht richtig encodet sind. * Eine aktuelle csa-ansible-role benutzt, die im Clusterbetrieb eine dritte Elasticsearch Instanz (auf dem Nodeswitch) erwartet. # 2.7.0 * Management-Schnittstellen JMX over HTTP Unterstützung (jolokia) hinzugefügt * Crawler Management Endpoint zum setzen des crawler nodeState='active' oder 'standby' hinzugefügt * In Docker-Containern wird ab sofort die Logausgabe auf die Konsole geschrieben. Vorher waren in der GitLab-Pipeline Root-Rechte erforderlich, um die Log-Datei in das Volume `/logs` zu schreiben. * Dockerfiles optimiert * Bild-Targets "integration-test" und "production" * Root-User nur noch bei integration-test targets # 2.6.1 * docker images - docker start.sh auf .env Datei umgestellt, so wird immer das aktuellste Image benutzt - docker-compose.yml hinzugefügt und nutzt auch die .env Datei * Umstellung auf Gitlab Package Registry * CSA Ansible Role ausgelagert in ein eigenes Git Projekt und als Git Submodule ins CSA Projekt wieder integriert * AEMCSAClientVDEK Client Code aus allgemeinen CSA Code gelöscht # 2.6.0 * Der Document.filetype unterliegt nun keinen Einschränkung mehr, da er nicht konfigurierbar ist und über die Include/Exclude Patterns sind Indexierungen grundsätzlich abfangbar. # 2.5.0 * Die Tika Methode des CrawlerController funktioniert jetzt ohne, dass ein Crawler extra angelegt werden muss. Es nutzt aber weiterhin einige Klassen des Crawlers um die Authentisierung und Tika zu gewährleisten. # 2.4.2 * Die CSA Konfiguration wird im UTF-8 Format heruntergeladen. # 2.4.1 * Prefixe in Wörtern bei der Score Funktion search_promotion getrennt mit ':' erlaubt, vor allem bei Keywords kann das vorkommen. Bsp: farbe:rot, kategorie:expert # 2.4.0 * Ansible Rolle für die CSA Installation hinzugefügt # 2.3.0 * Prefixsuche auf Basis von NGrams * Volltextsuche muss jetzt explizit angegeben werden, so das auch Felder von Type=text aus der Suche ausgenommen werden können * PPP-516: FunctionScore search_promotion für Type=keyword und Type=text hinzugefügt * PPP-556: CSA Such-Anfrage als POST-Request * Highlight-Tags und Did-you-mead/Suggest-Tags werden, zusätzlich zum SearchResult im HTML Format, nun auch im Json Format verwendet * dafür gibt es jetzt auch eine Templateangabe im searchJson Endpunkt * In den Values der Metadaten in HTML <head>-Tags werden jetzt alle HTML Tags entfernt. Bsp: <meta name="name" content="Eine HTML &Uuml;berraschung: <a href="blub.html">Link</a> <p><b>fett</b>!" /> wird in der CSA der String "Eine HTML Überraschung: <a href="blub.html">Link</a> <p><b>fett</b>!" und daraus wird alles HTML entfernt und es bleiben die anlysierten Worte (german Analyzer): "html uberraschung link fett" * PPP-569 gefixed. Der Crawler erinnert sich nun auch an invalidProcessed Urls, die noch nicht gelöscht wurden, vom letzten Durchlauf und kann daher beim nächsten Crawldurchlauf entscheiden, wie mit diesen invaliden URLs umgegangen wird. * PPP-559: Bugfix: Das Entfernen von Feldern oder einer Type-Änderung im Field Definition Mapping führt zu Problemen im Search Profile # 2.2.1 * PPP-430 Head Request im Crawler erlauben, dafür wurde die Checkbox in den Index Profiles im Admin wieder hinzugefügt * Neue Crawler-Endpoints hinzugefügt und Dokumentiert, die Auskunft über den Zustand einzelner Crawler geben. # 2.2.0 * PPP-340 Es gibt eine Filter Erweiterung im Search Service, alle Filter können jetzt negiert werden mit einem '!' an erster Stelle * Metadata im <head> Tag werden jetzt bei Änderungen beachtet, wenn sie in den Field Definition Mapping als Feldname meta_* und tika Property Name "META" markiert sind. # 2.1.0 * CSA Spring Boot auf Version 2.3.3 erhöht * CSA Monitor/Spring Boot Admin auf Version 2.3.0 erhöht * customRefresh Url von Search und Index entfernt und durch die Management /refresh URL ersetzt * Jefmonitor kann jetzt über Zuul betrieben werden, ohne das die Cookies vom Admin und Jefmonitor sich stören * Neue Swagger Version 1.46 von springdoc benutzt * Prometheus Support * Alte config und configs Verzeichnisse entfernt, configes bleibt und ist jetzt allein und nicht mehr verwirrend * ESClient ausgetauscht mit dem von Spring Boot 2 mitgebrachten * auf Junit 5 und Assertj umgestellt * Die CSA läuft nun auf Java 11. # 2.0.0 * CMSVDEK-174 Update der CSA auf die aktuelle Elasticsearch Version 7.5.X * Asciidoc Dokumentation hinzugefügt und als Single-Page Html Dokumentation unter der Admin GUI verfügbar * Test GUI Link zur Admin GUI hinzugefügt * CSADEV-324 Typeahead auf eine neue Variante umgestellt, die nun auch Filterung, Boost, IncludePatterns/ExcludePatterns und Size als Parameter erlaubt.